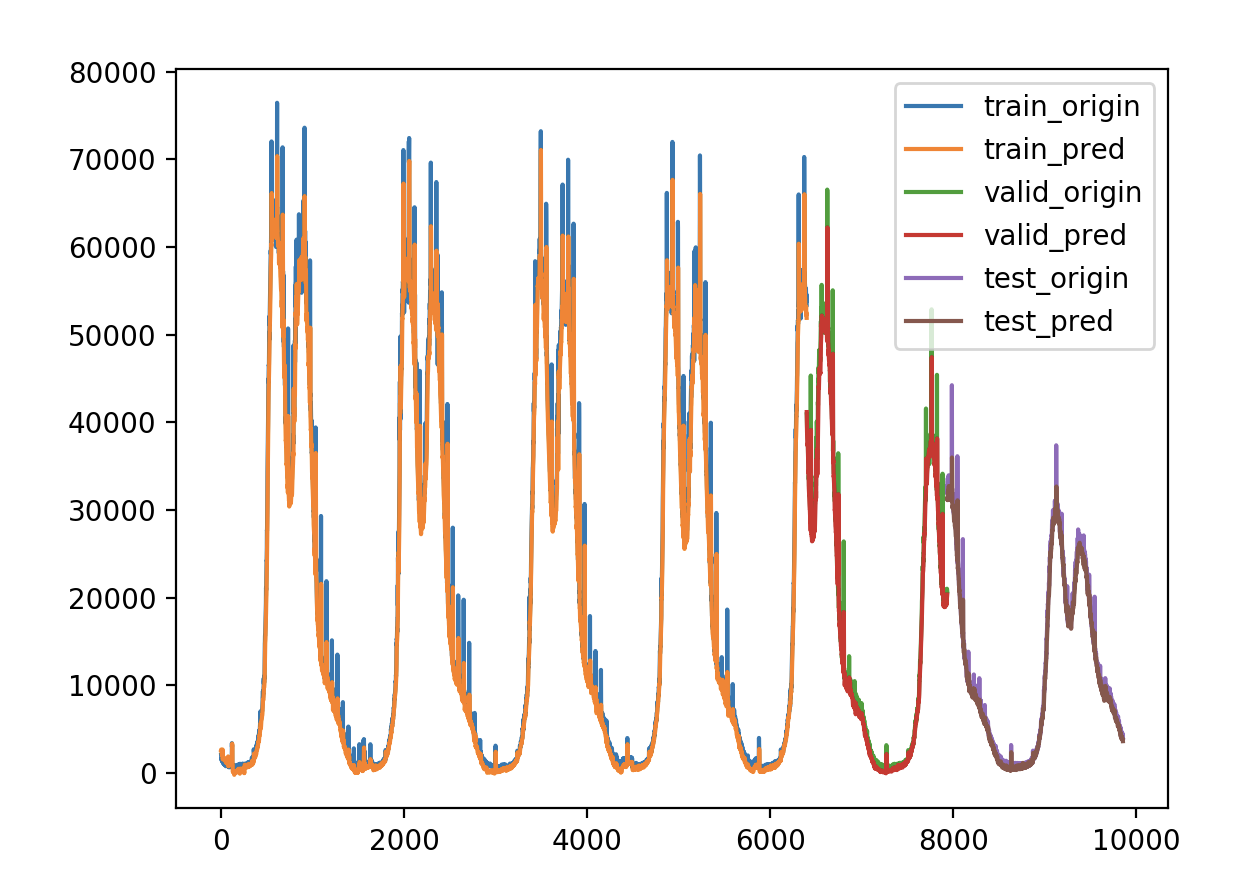
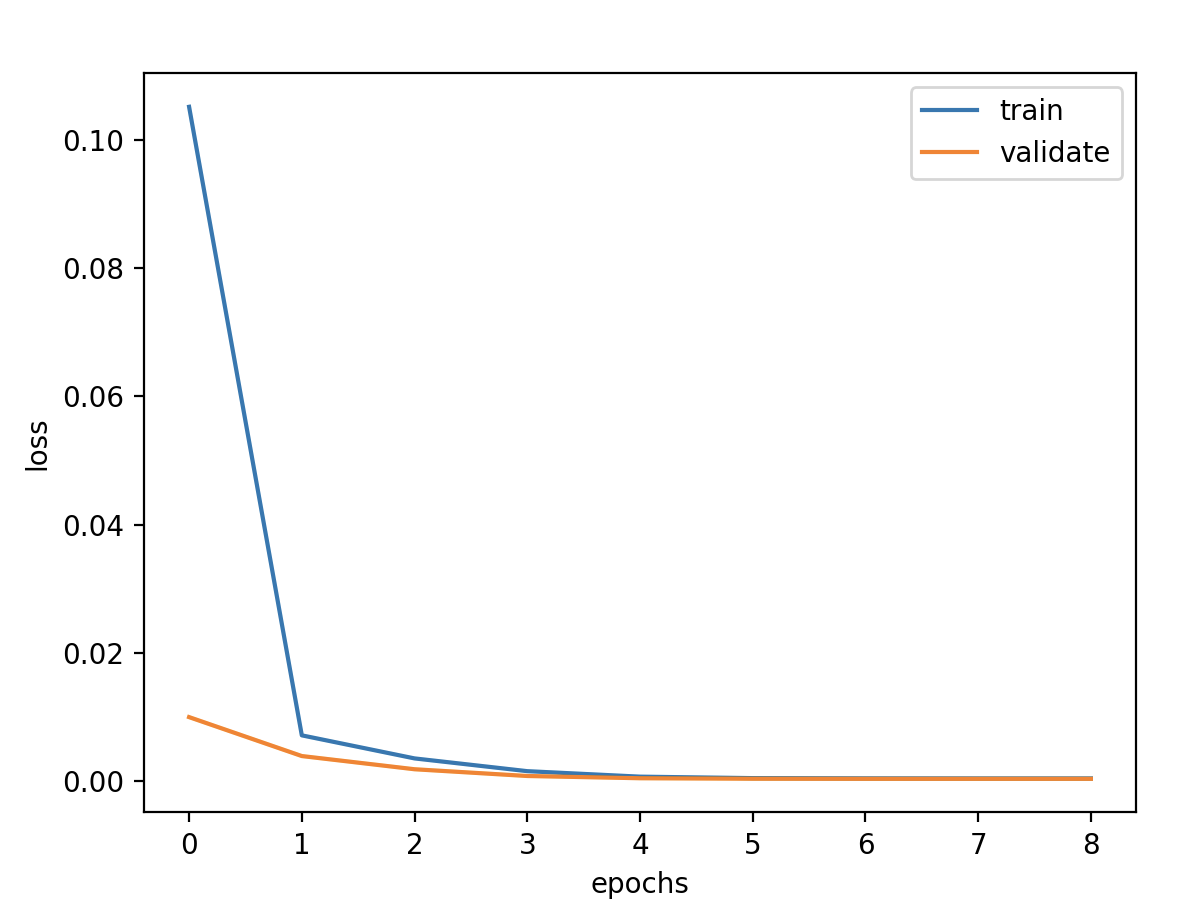
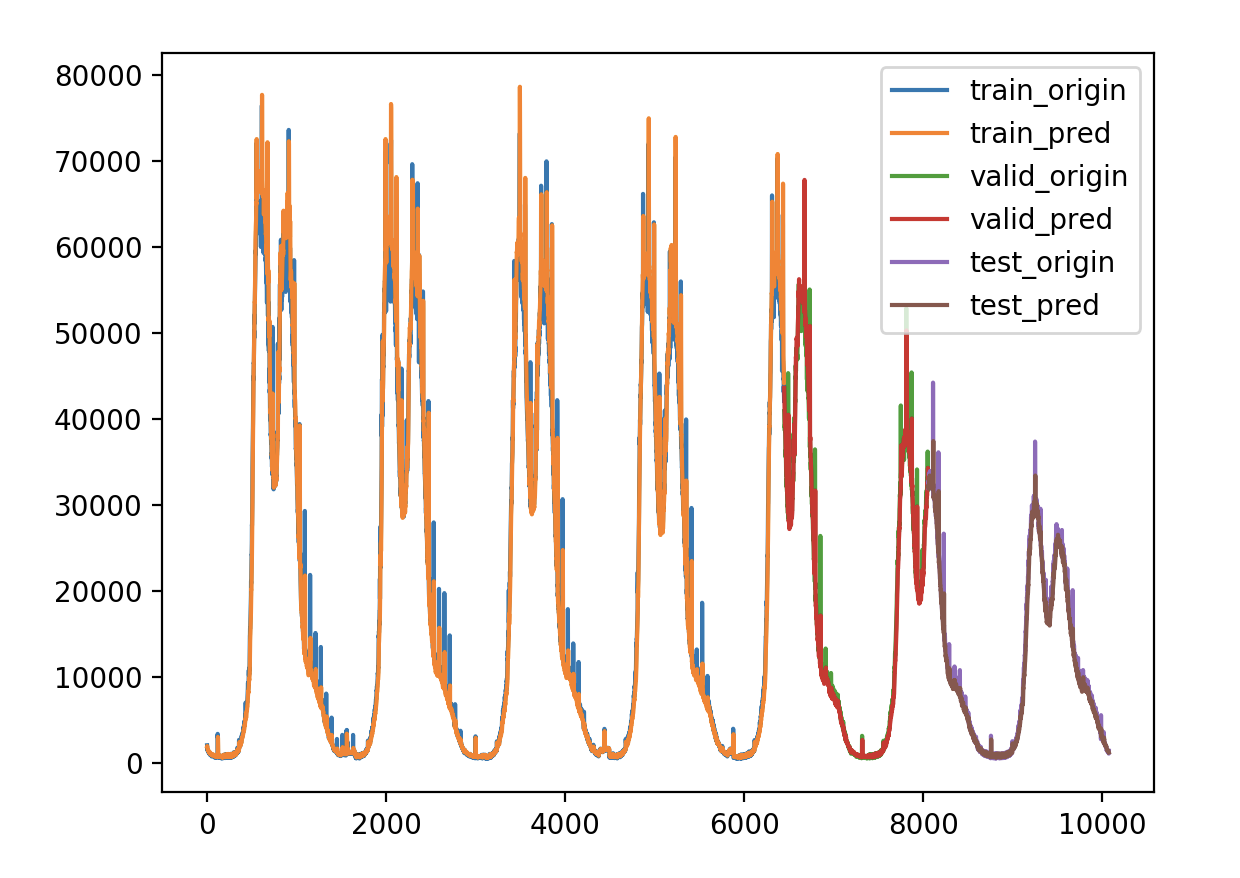
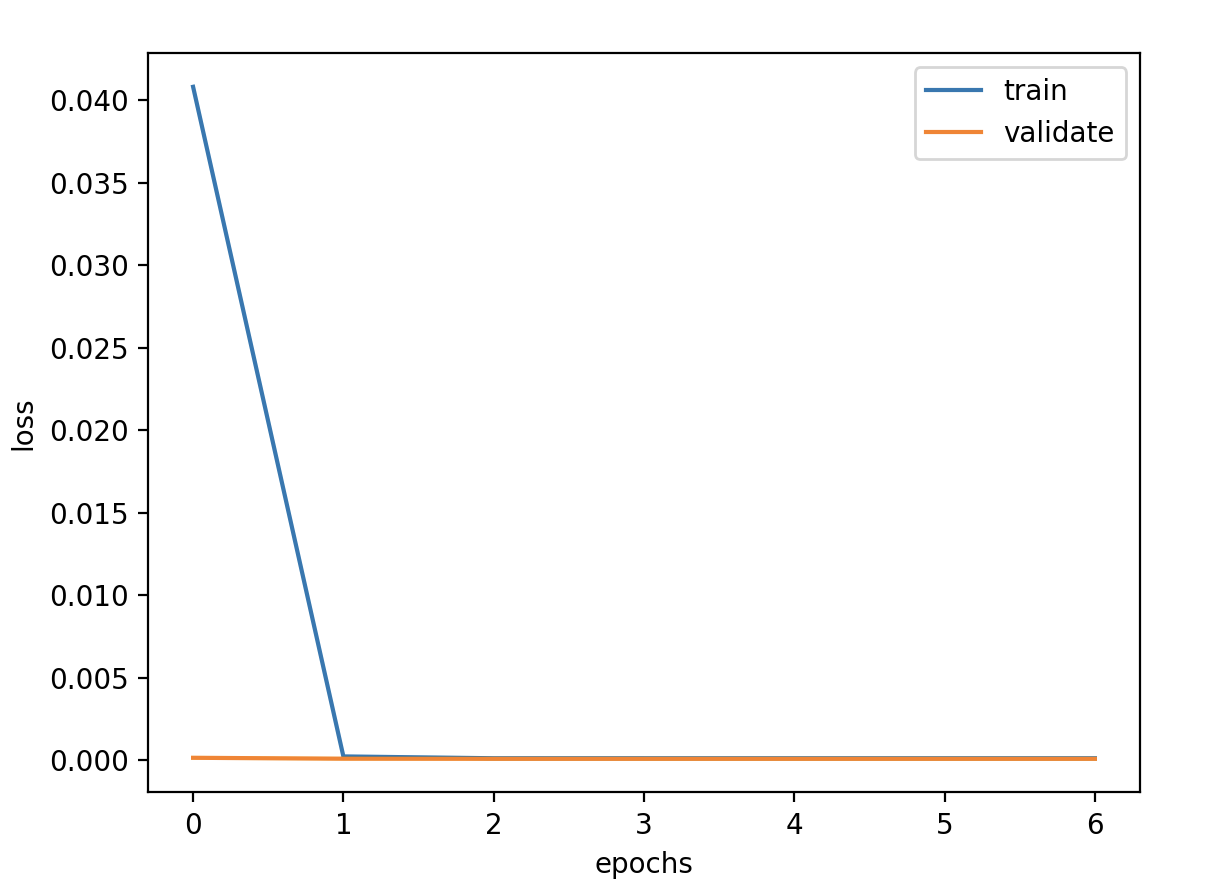
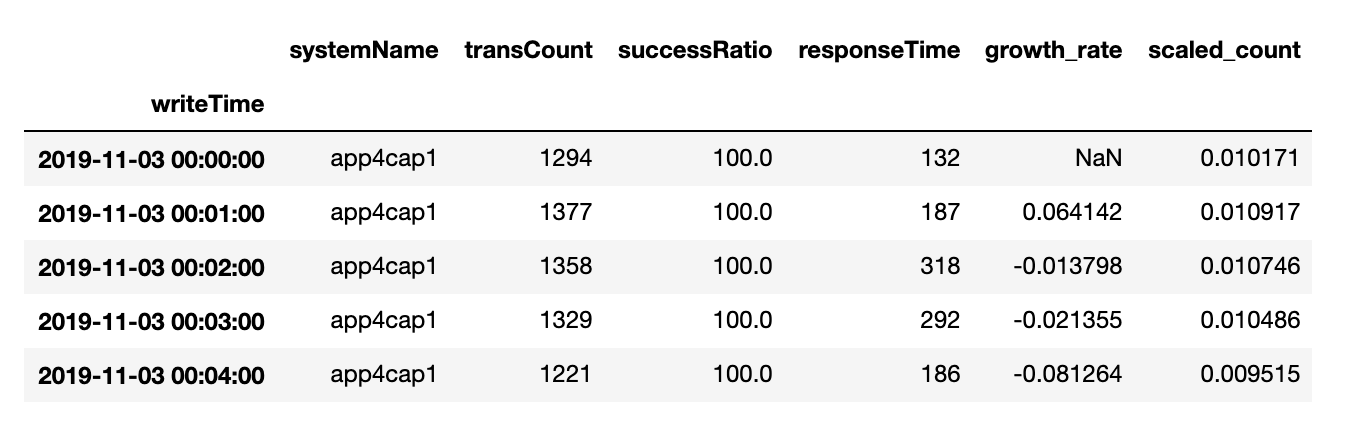
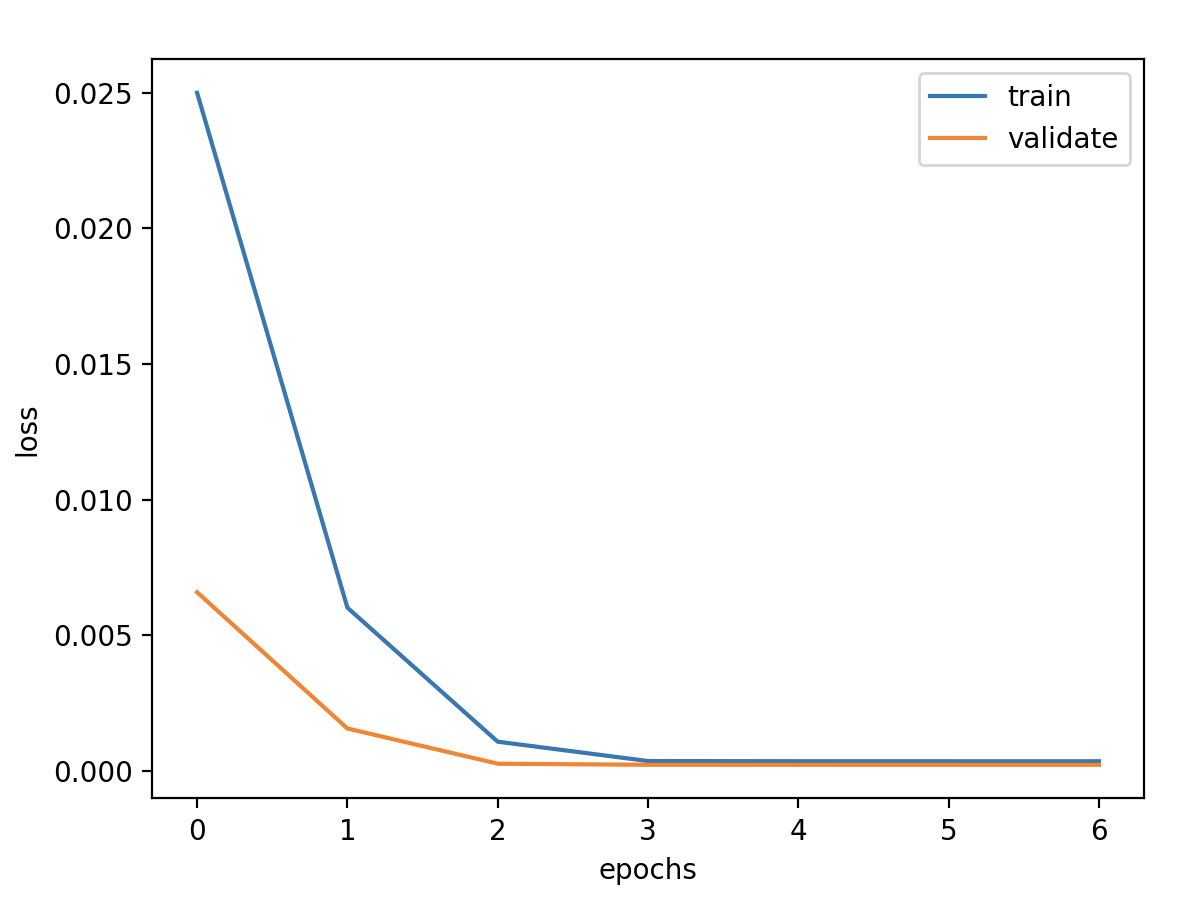
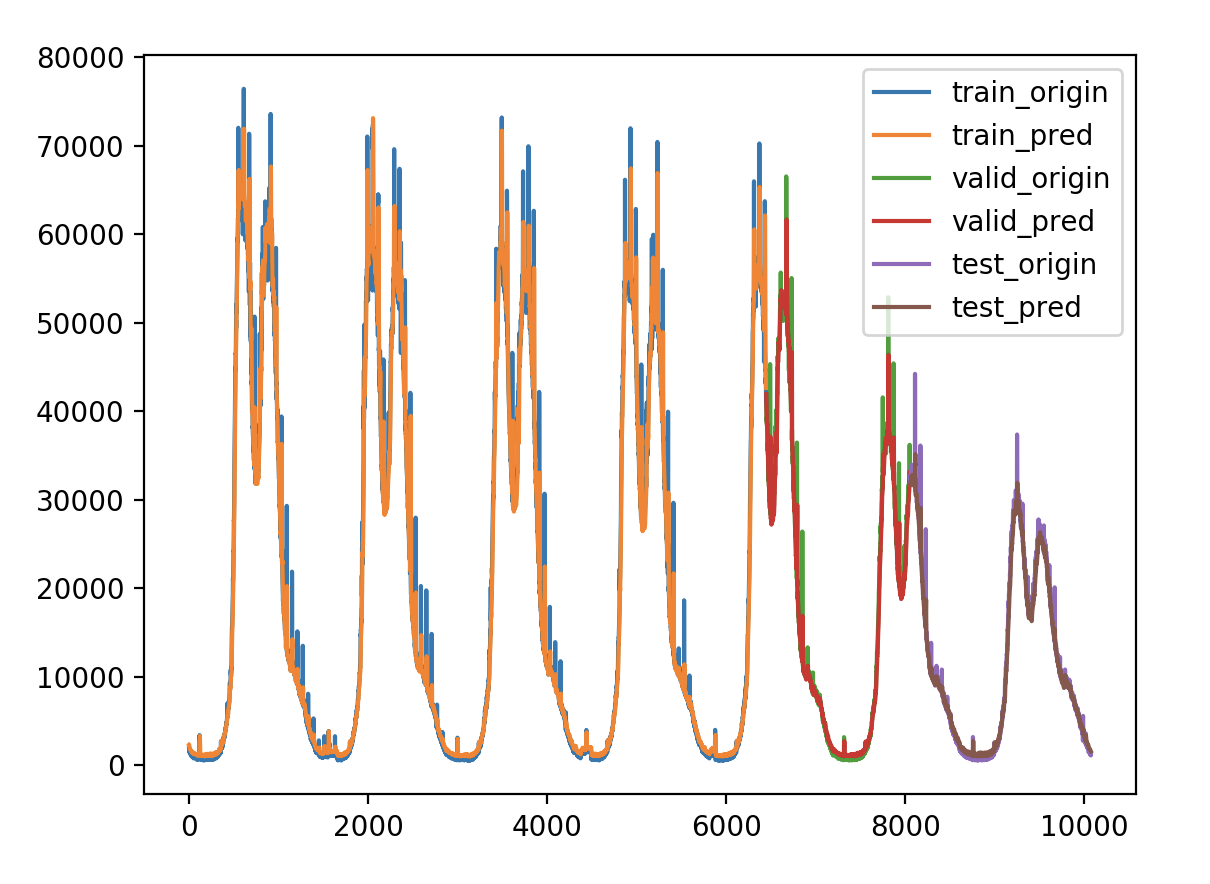
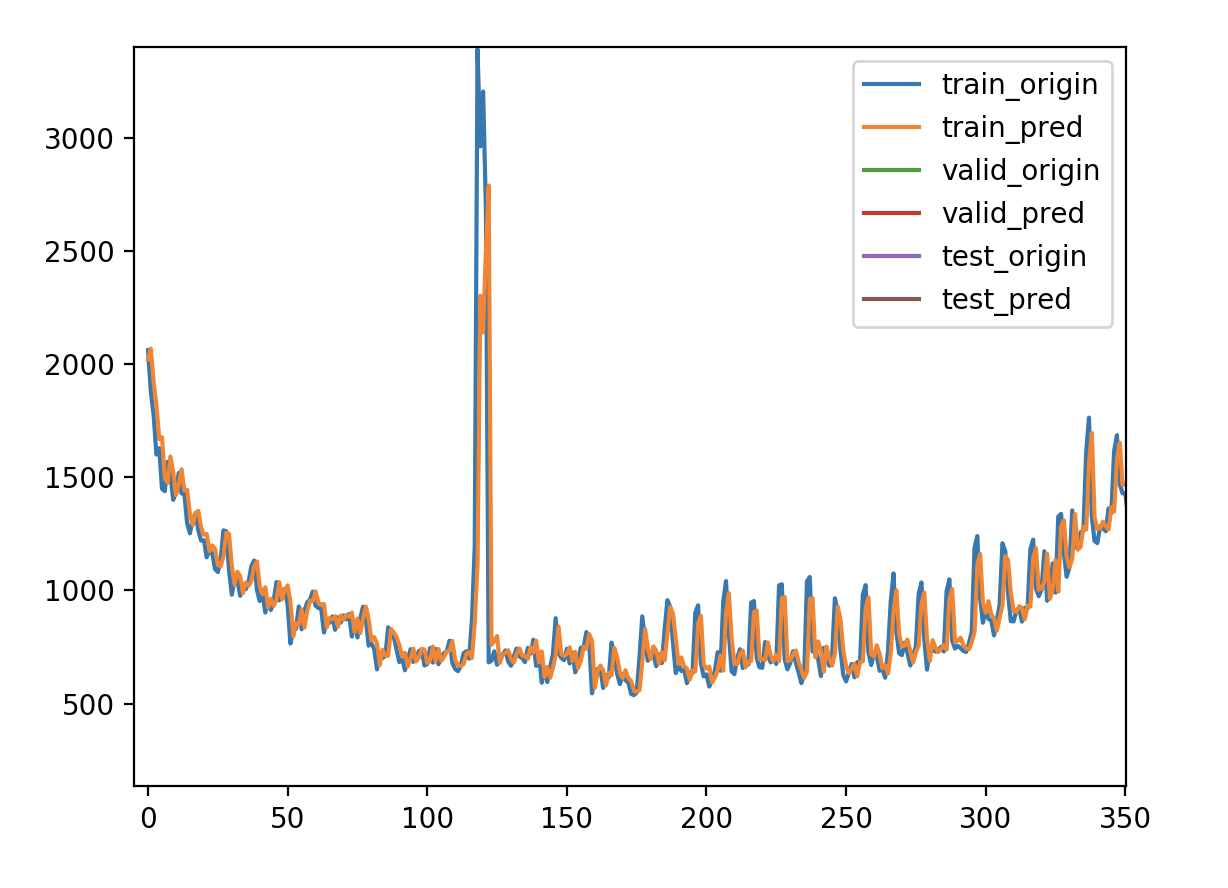
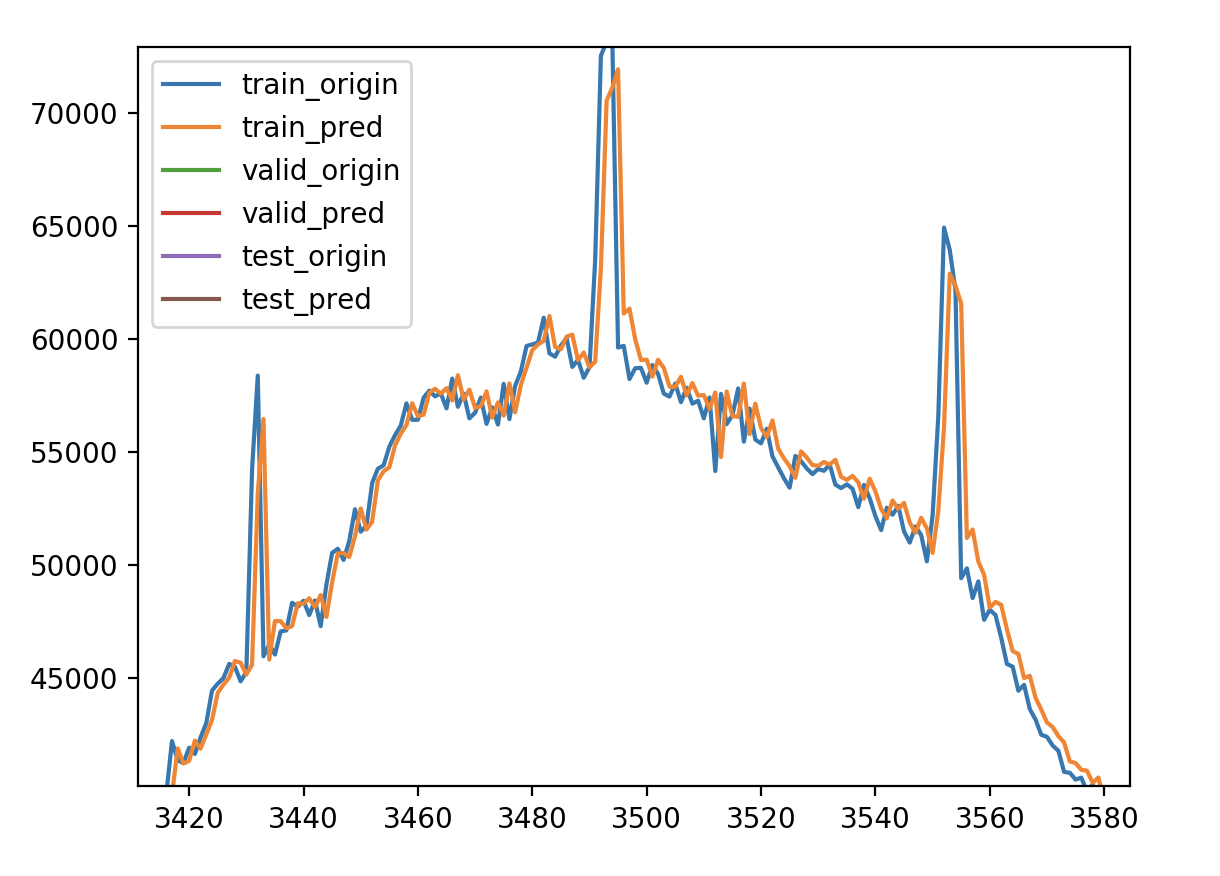
调节内容 1.输出维度 units
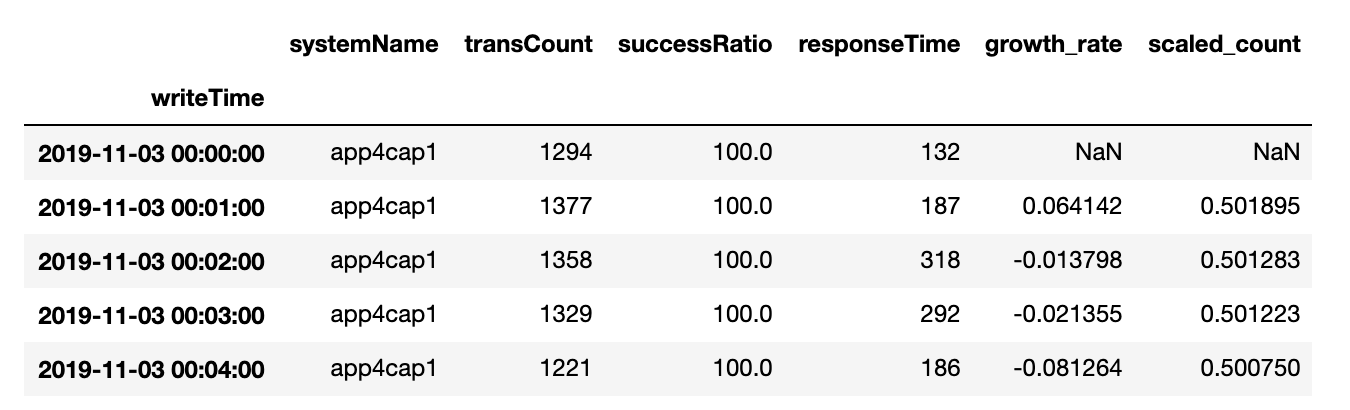
原始数据集
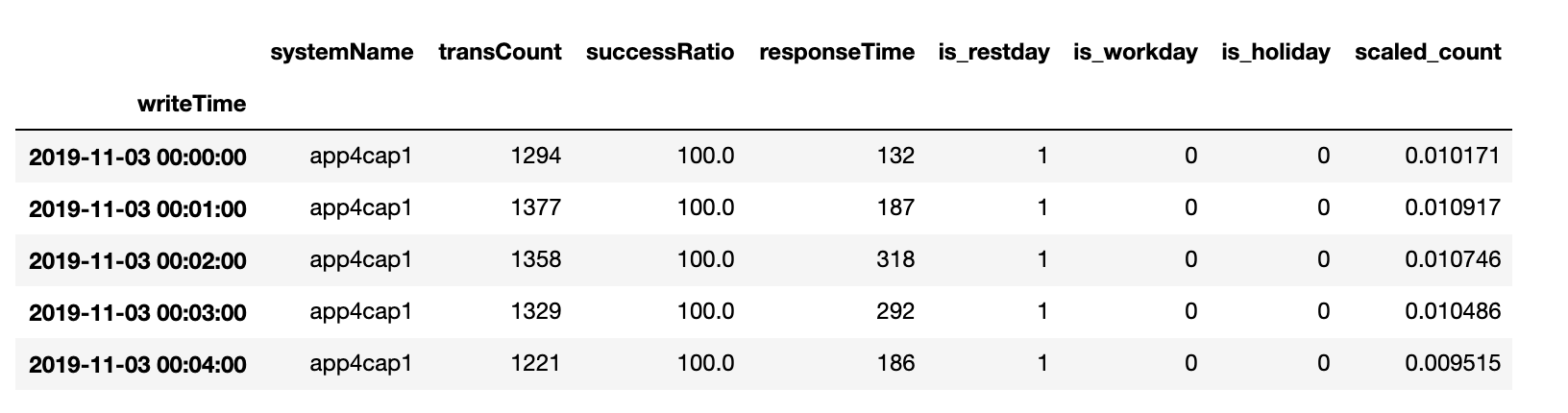
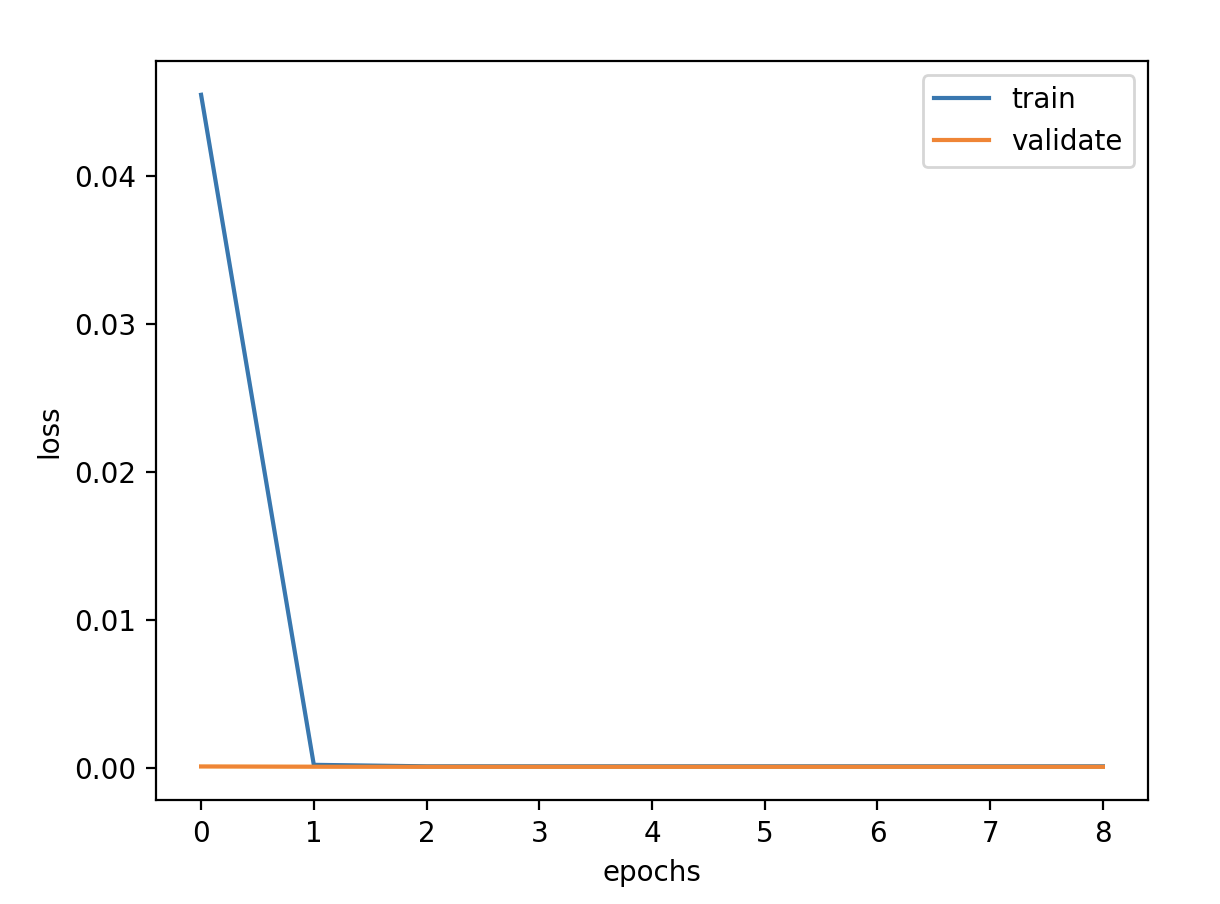
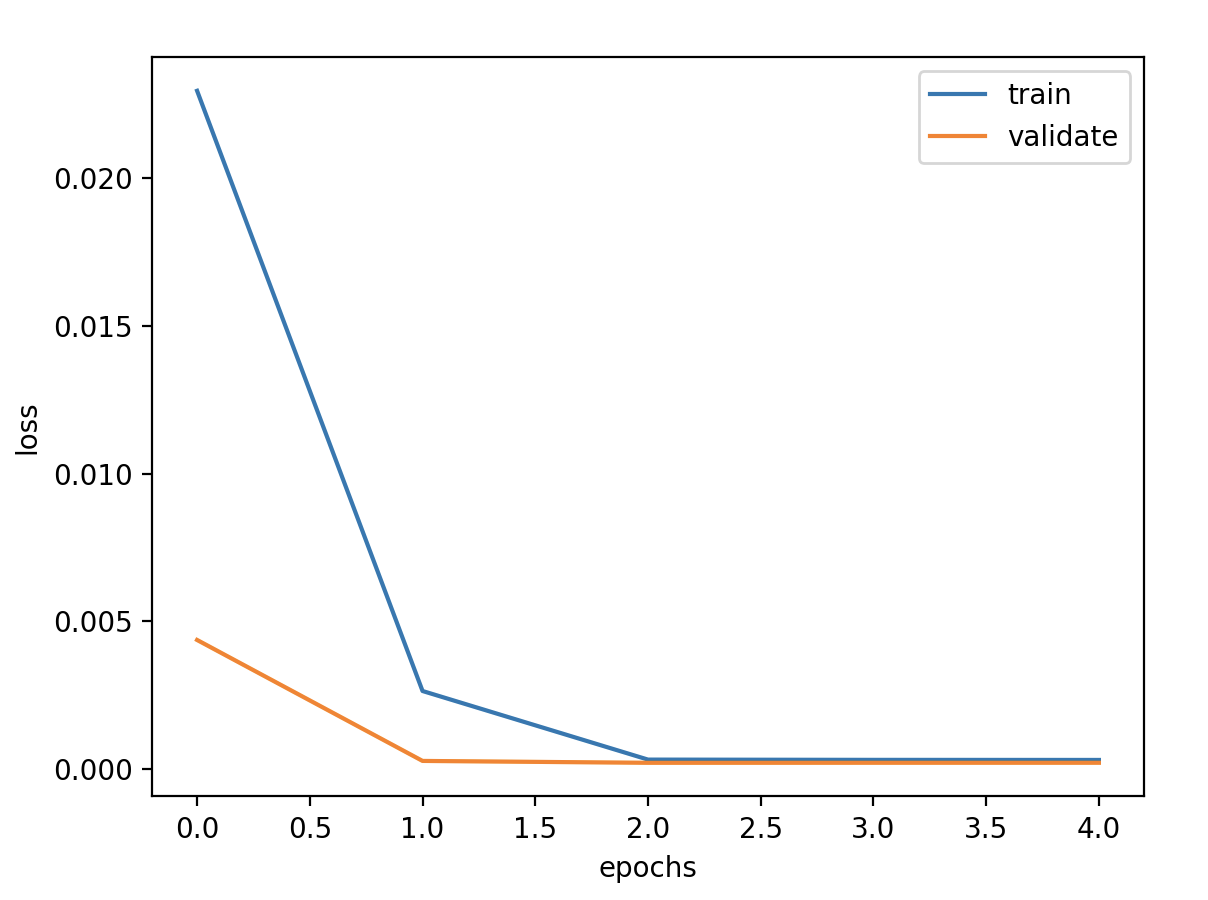
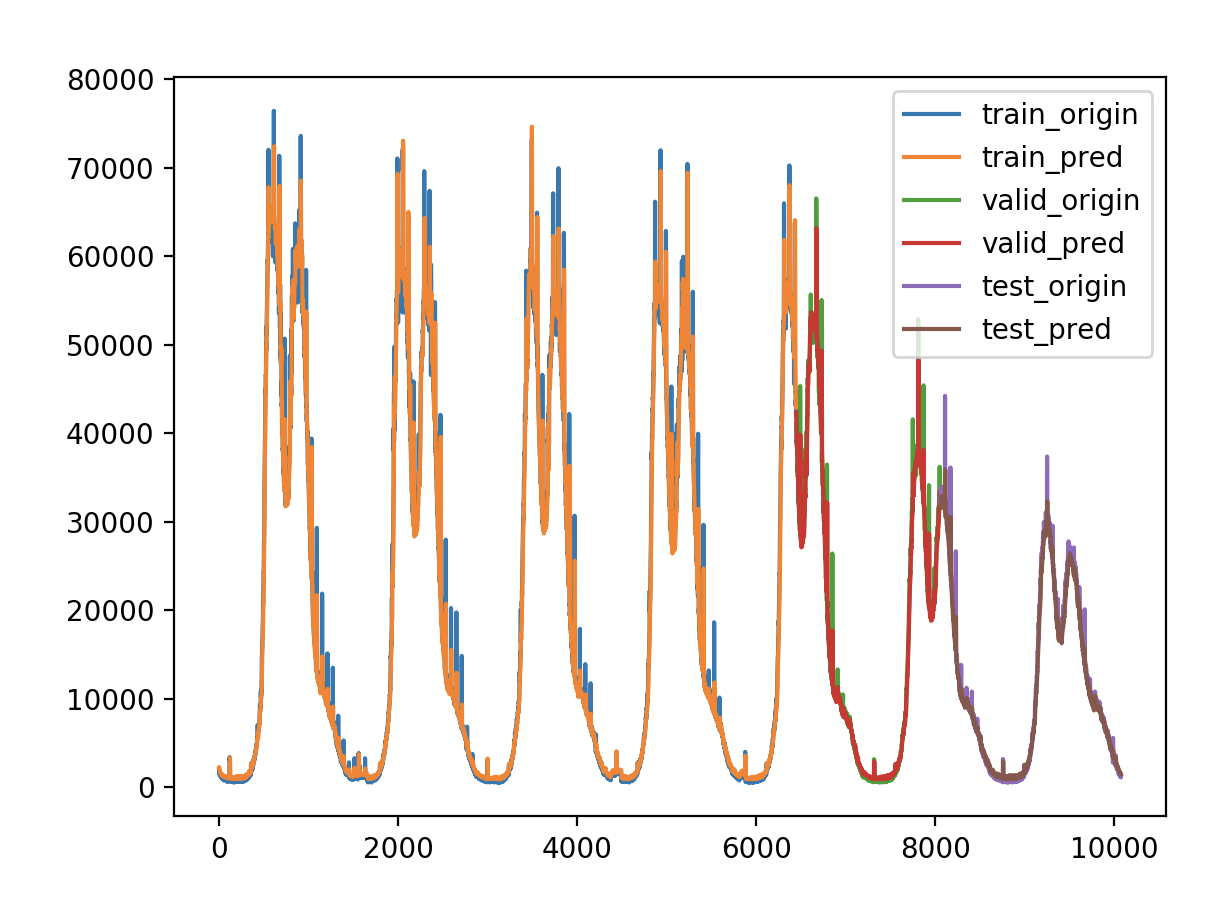
原始序列 超参数 1 2 3 4 5 6 7 8 # 定义超参数 batch_size = 128 # 批数据大小 epochs = 50 # 实验训练次数 units = 64 # 状态的输出维度 features = 1 # 最终输出维度 timesteps = 3 # 时间步长 feature_range = (0, 1) # 归一化值域 ratio = 0.8 # 数据集分割比例
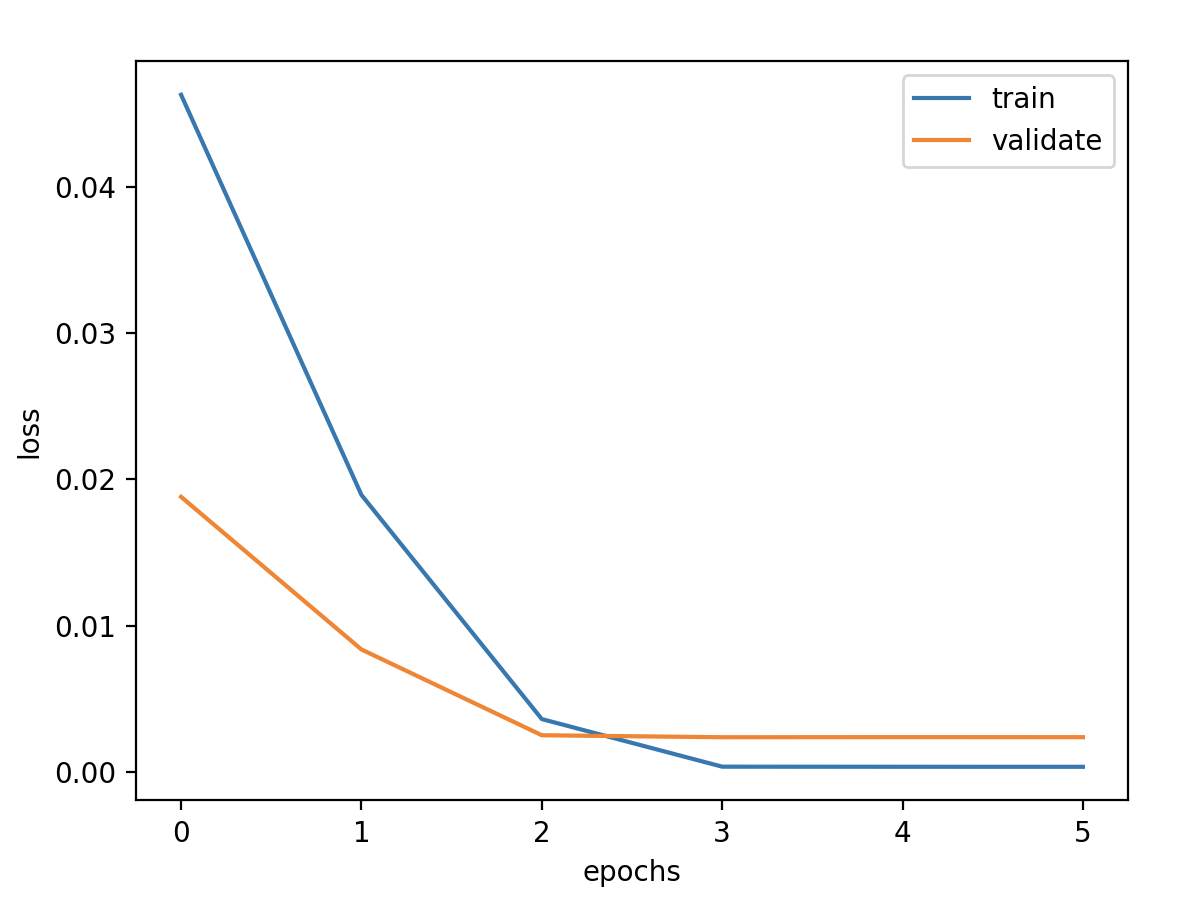
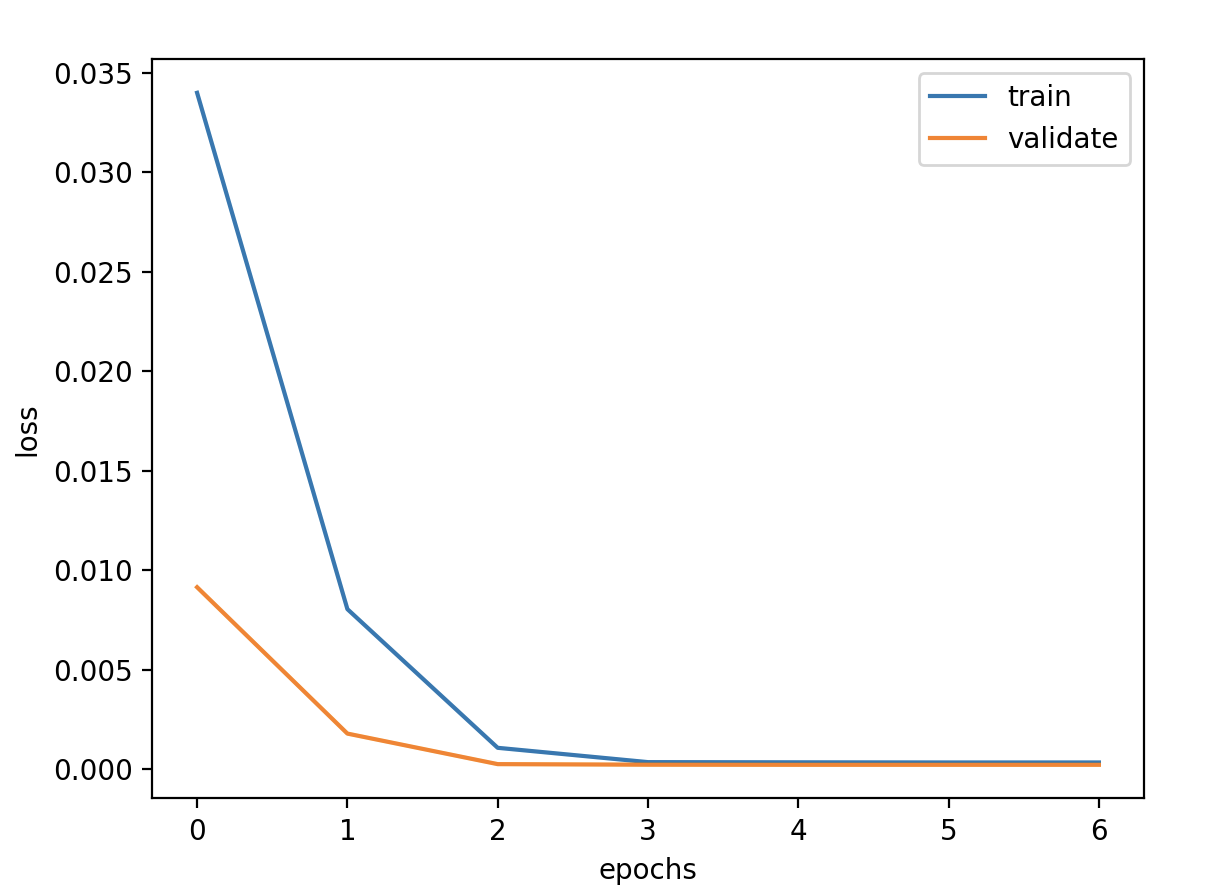
模型定义 1 2 3 4 5 6 7 8 9 10 11 12 13 model = Sequential() model.add(LSTM(units=units, activation='tanh' , input_shape=(timesteps,features))) model.add(Dense(1 )) model.compile (loss='mse' , optimizer='adam' ) callbacks = [ keras.callbacks.EarlyStopping(monitor='val_loss' , patience=2 ), keras.callbacks.ModelCheckpoint(filepath='model.h5' , monitor='val_loss' , save_best_only=True ), keras.callbacks.ReduceLROnPlateau(monitor='val_loss' , factor=0.01 , patience=2 ) ] history = model.fit(x_train, y_train, epochs=epochs, batch_size=batch_size, validation_data=(x_valid, y_valid), callbacks=callbacks, verbose=1 )
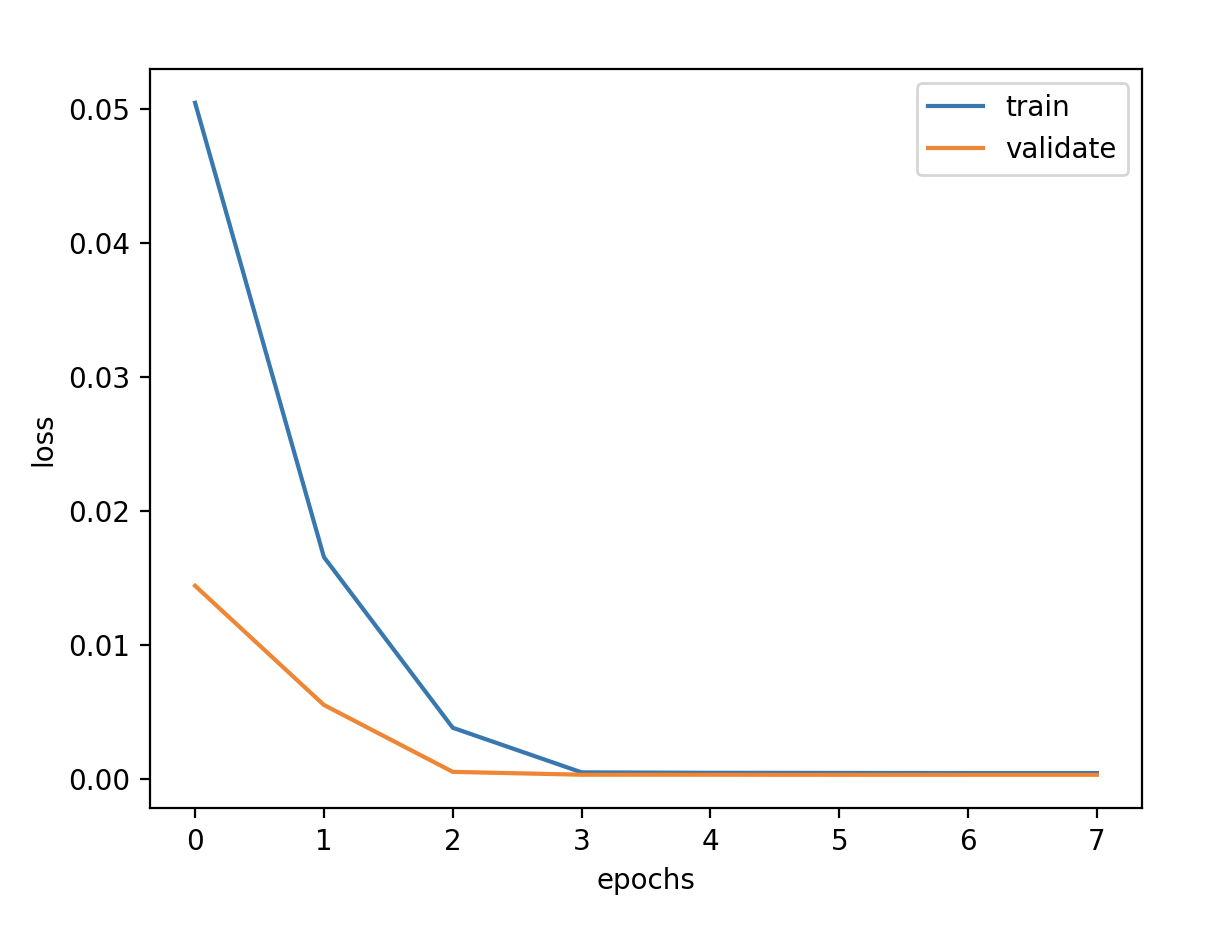
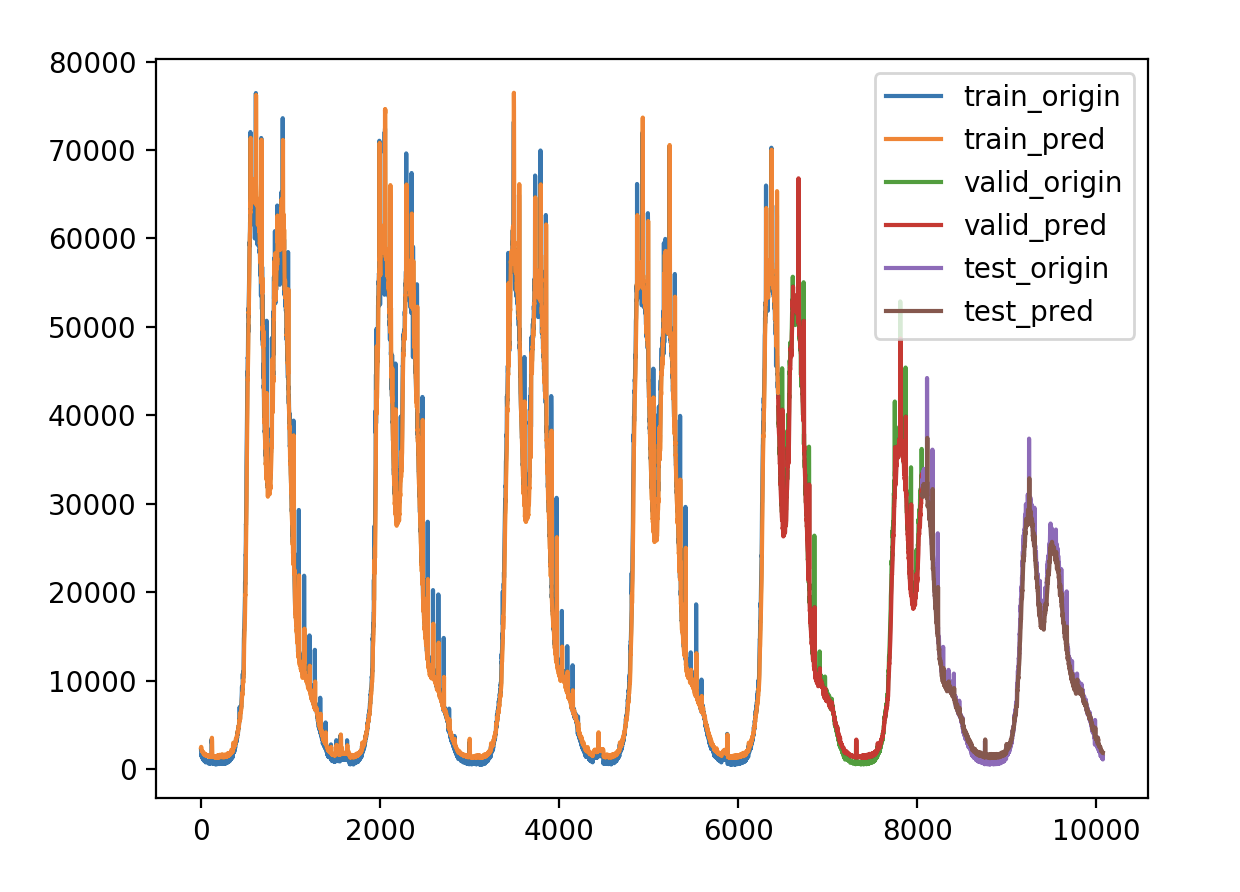
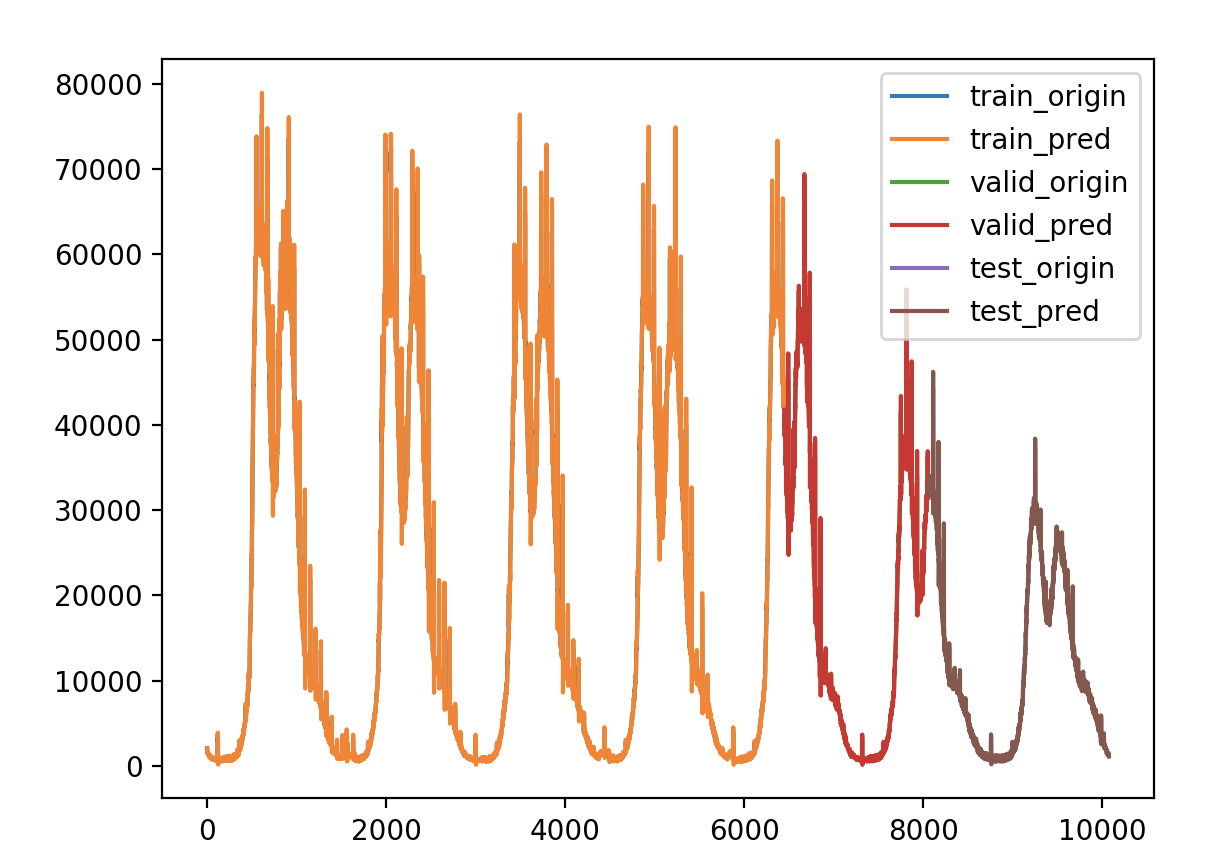
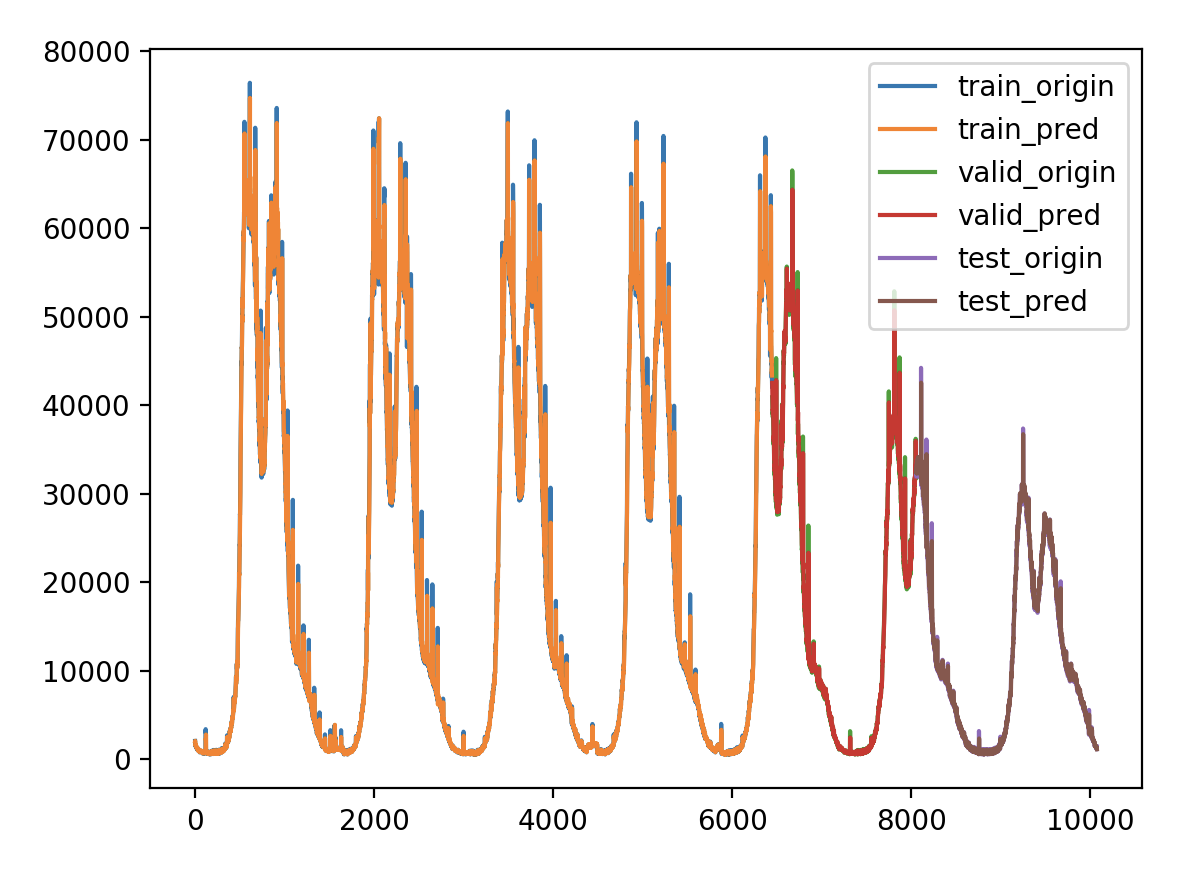
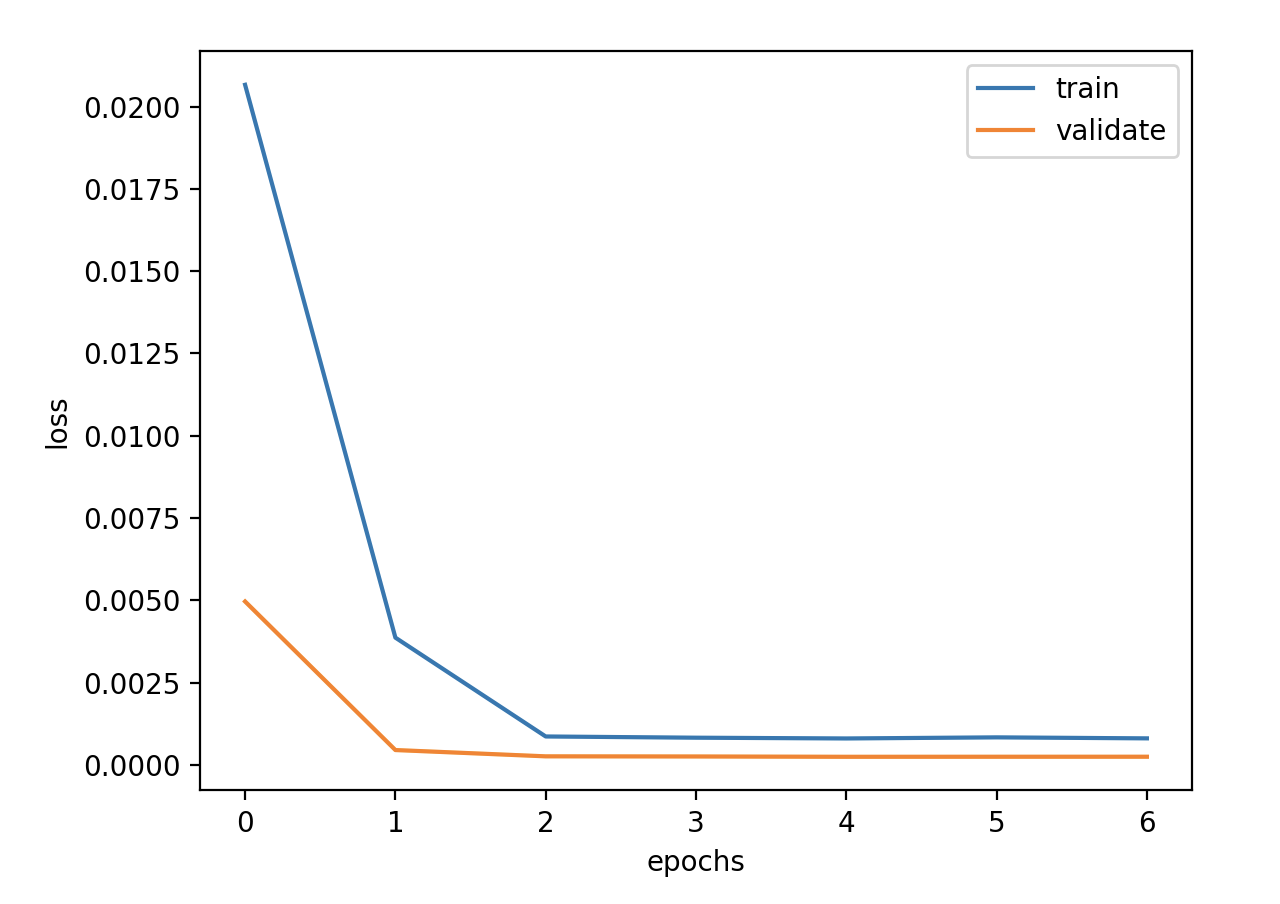
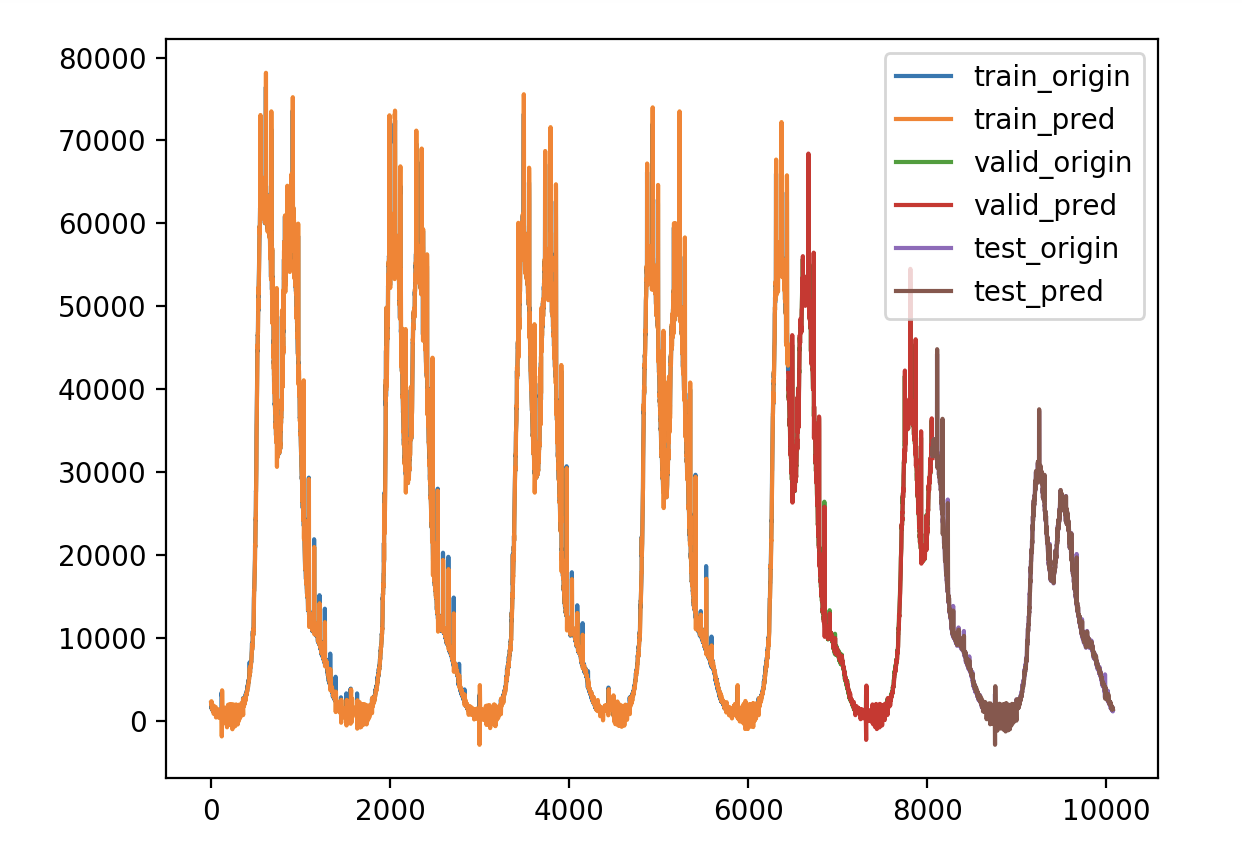
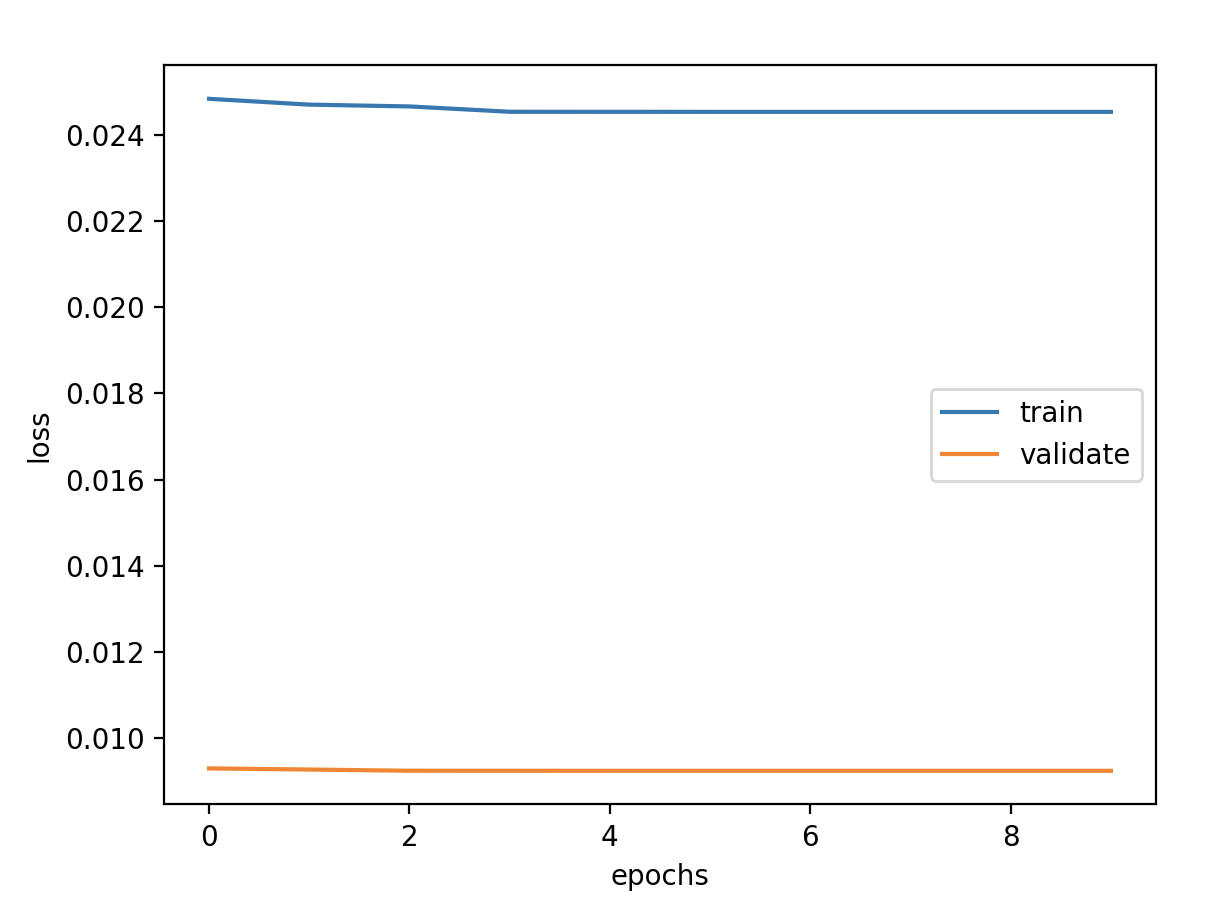
验证损失 1 2 3 4 5 validate cost: 0.00031516602518997155 elapsed time: 2.2270960807800293 (s) Train Score: 2350.04 RMSE Valid Score: 1975.81 RMSE Test Score: 1143.96 RMSE
Stateful LSTM 使 RNN 具有状态意味着每批样品的状态将被重新用作下一批样品的初始状态。
stateful LSTM:能让模型学习到你输入的samples之间的时序特征,适合一些长序列的预测,哪个sample在前,那个sample在后对模型是有影响的。
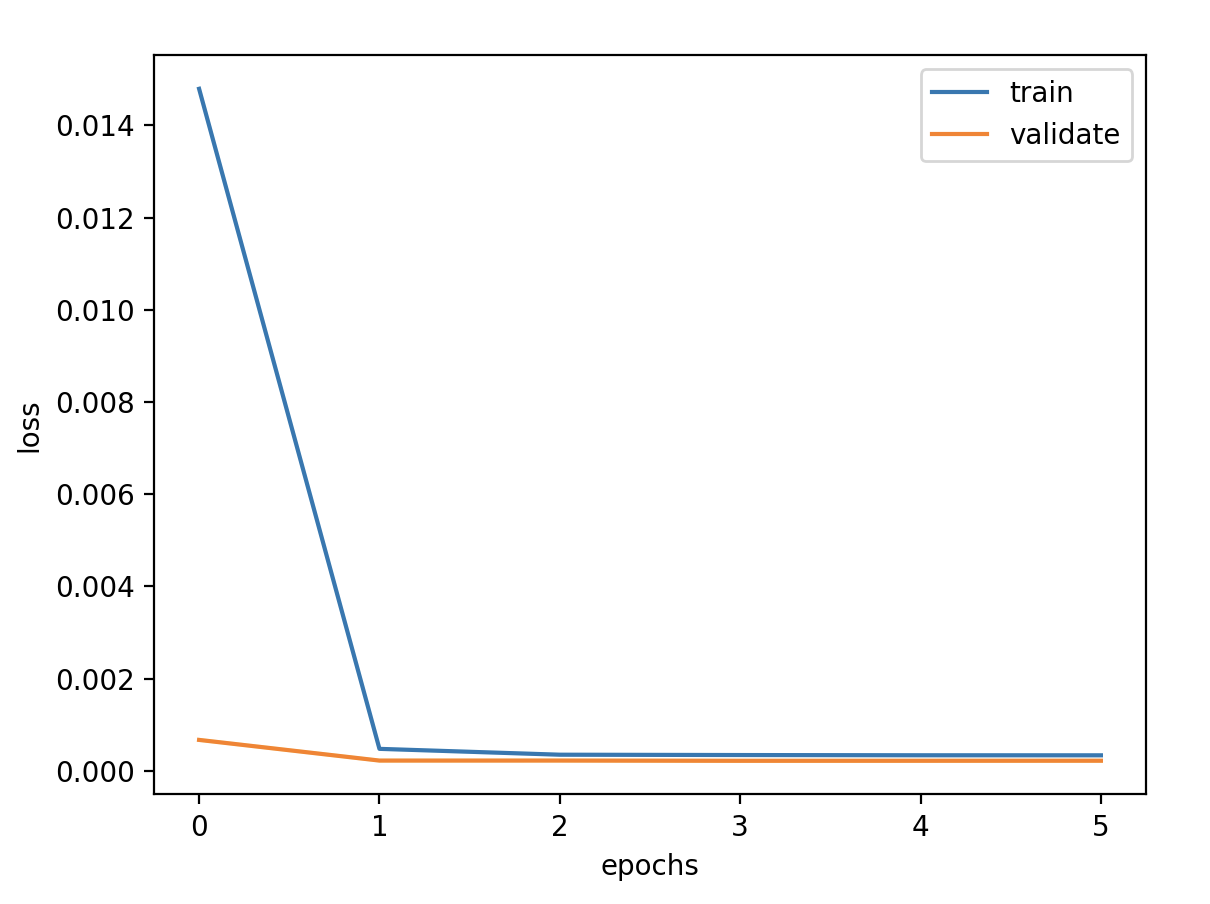
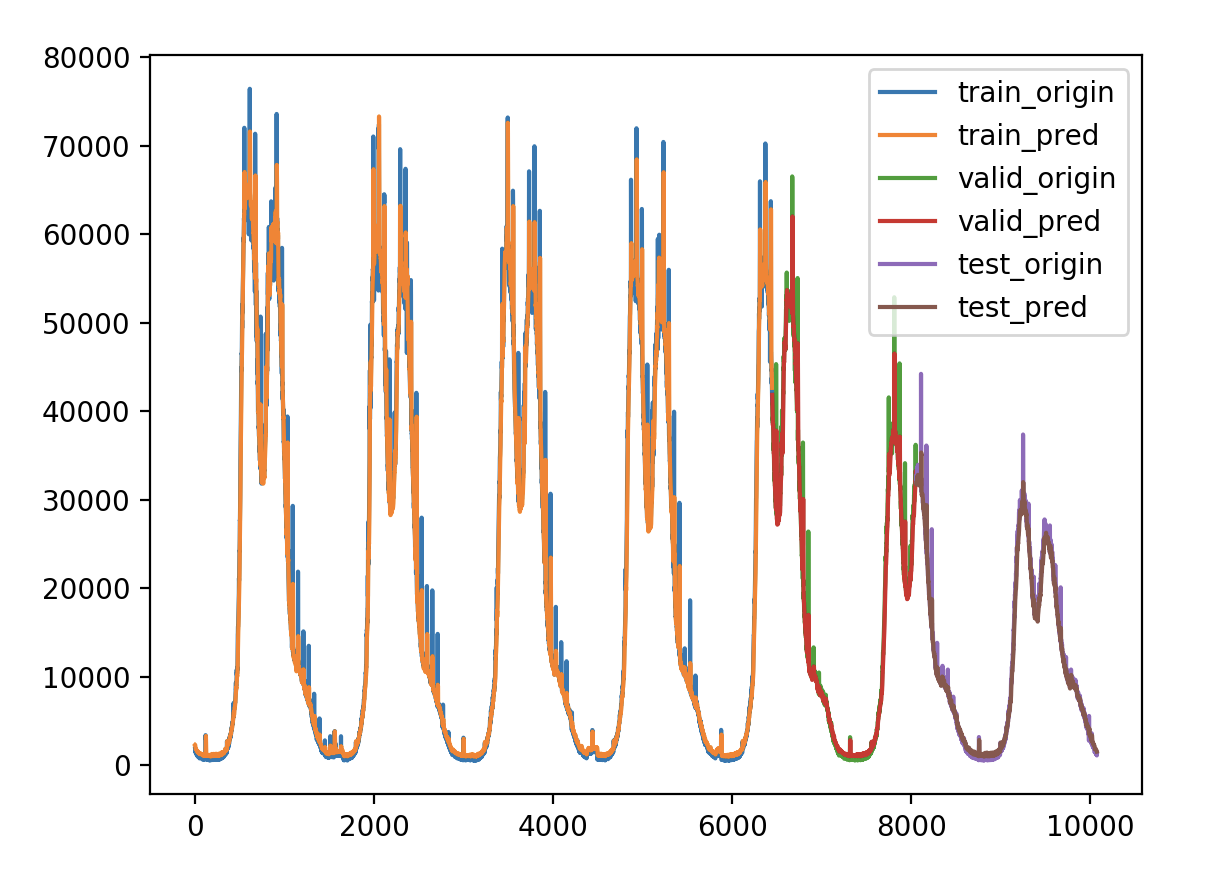
超参数 1 2 3 4 5 6 7 8 # 定义超参数 batch_size = 128 # 批数据大小 epochs = 50 # 实验训练次数 units = 64 # 状态的输出维度 features = 1 # 最终输出维度 timesteps = 3 # 时间步长 feature_range = (0, 1) # 归一化值域 ratio = 0.8 # 数据集分割比例
模型定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 model = Sequential() model.add(LSTM(units=units, activation='tanh' , stateful=True , batch_input_shape=(batch_size, timesteps, features))) model.add(Dense(1 )) model.summary() callbacks = [ keras.callbacks.EarlyStopping(monitor='val_loss' , patience=2 ), keras.callbacks.ModelCheckpoint(filepath='model.h5' , monitor='val_loss' , save_best_only=True ), keras.callbacks.ReduceLROnPlateau(monitor='val_loss' , factor=0.01 , patience=2 ) ] model.compile (loss='mse' , optimizer='adam' ) for i in range (epochs): history = model.fit(x_train, y_train, batch_size=batch_size, epochs=1 , verbose=1 , validation_data=(x_valid, y_valid), shuffle=False , callbacks=callbacks) model.reset_states()
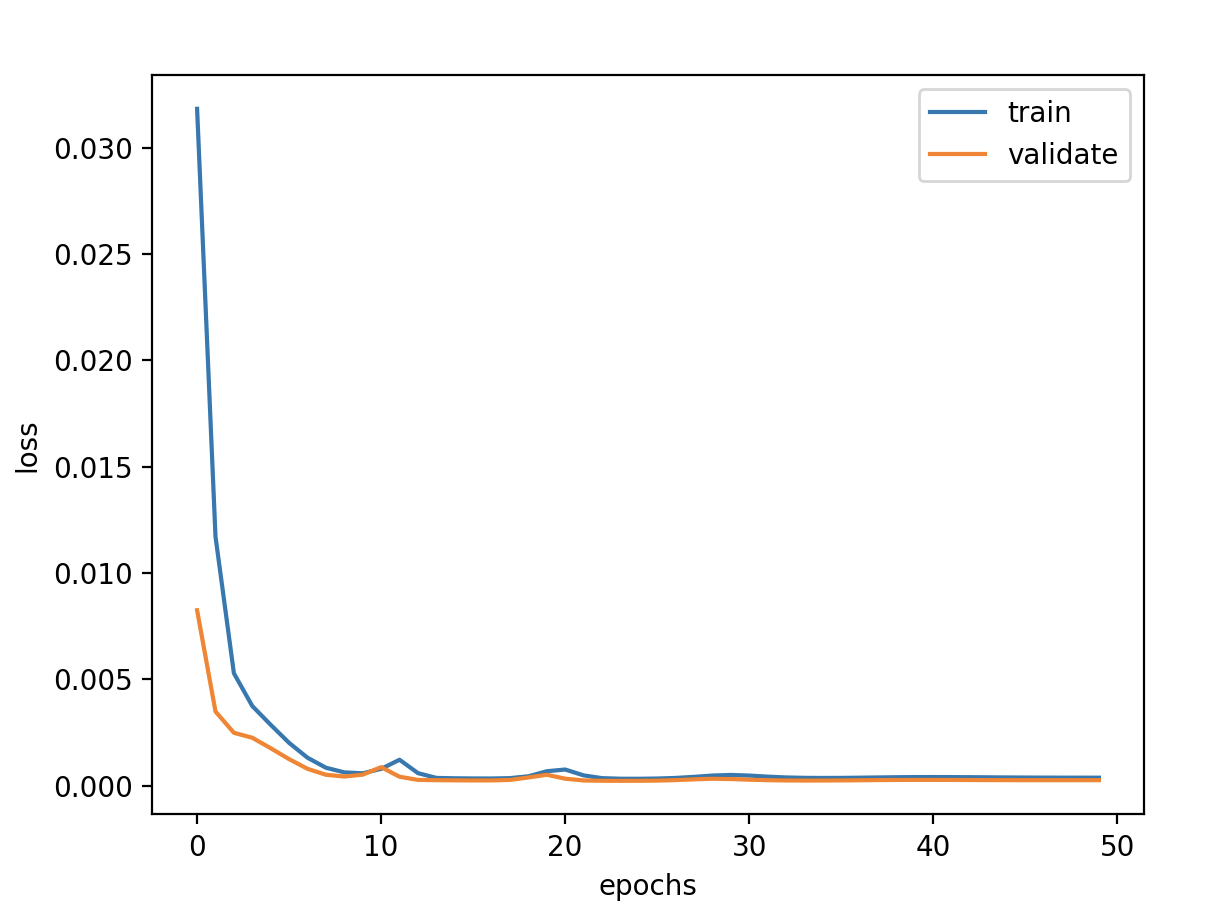
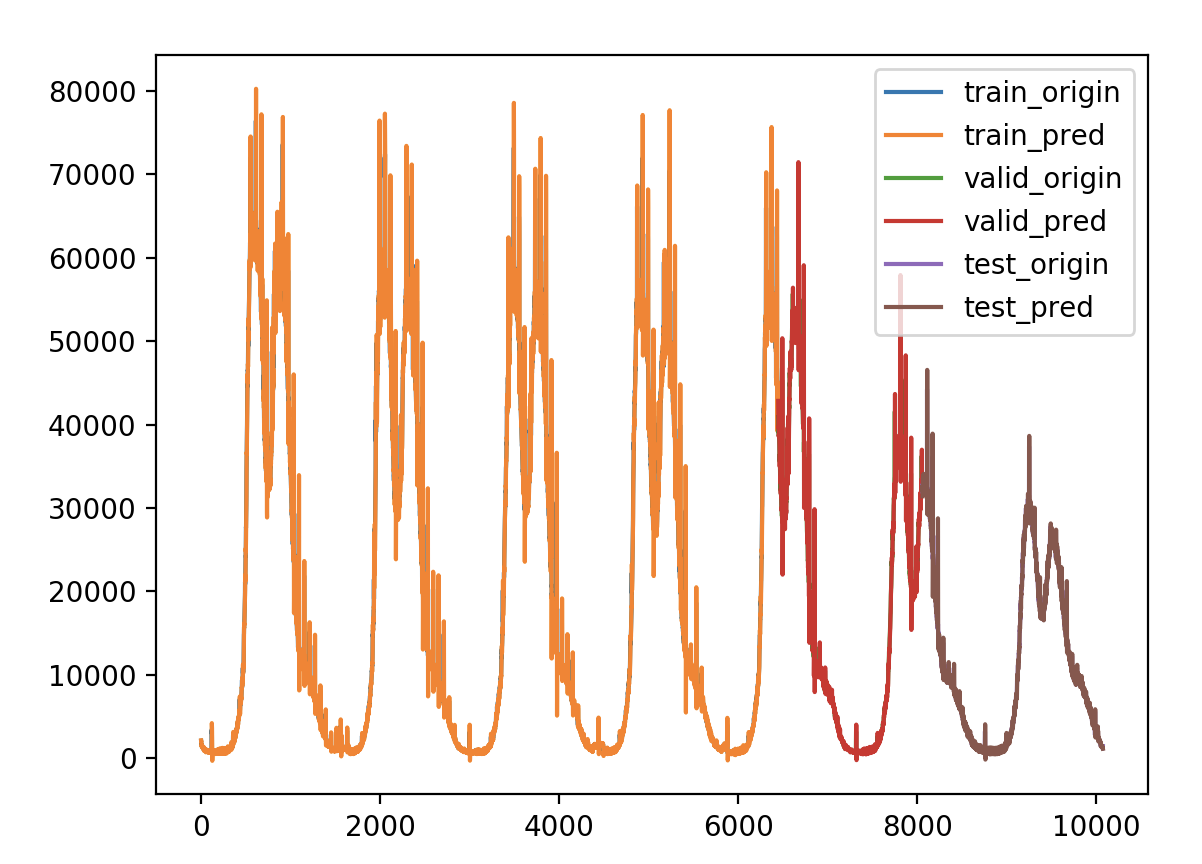
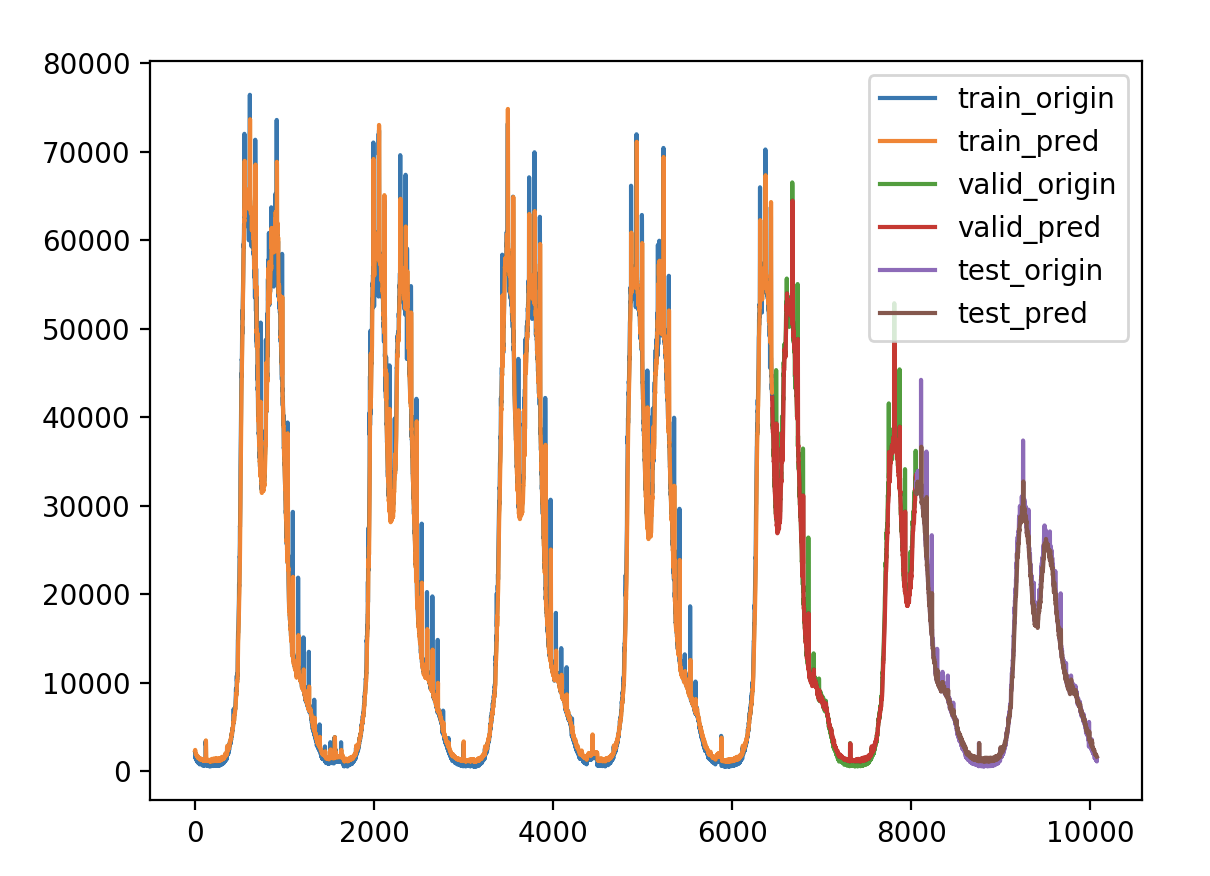
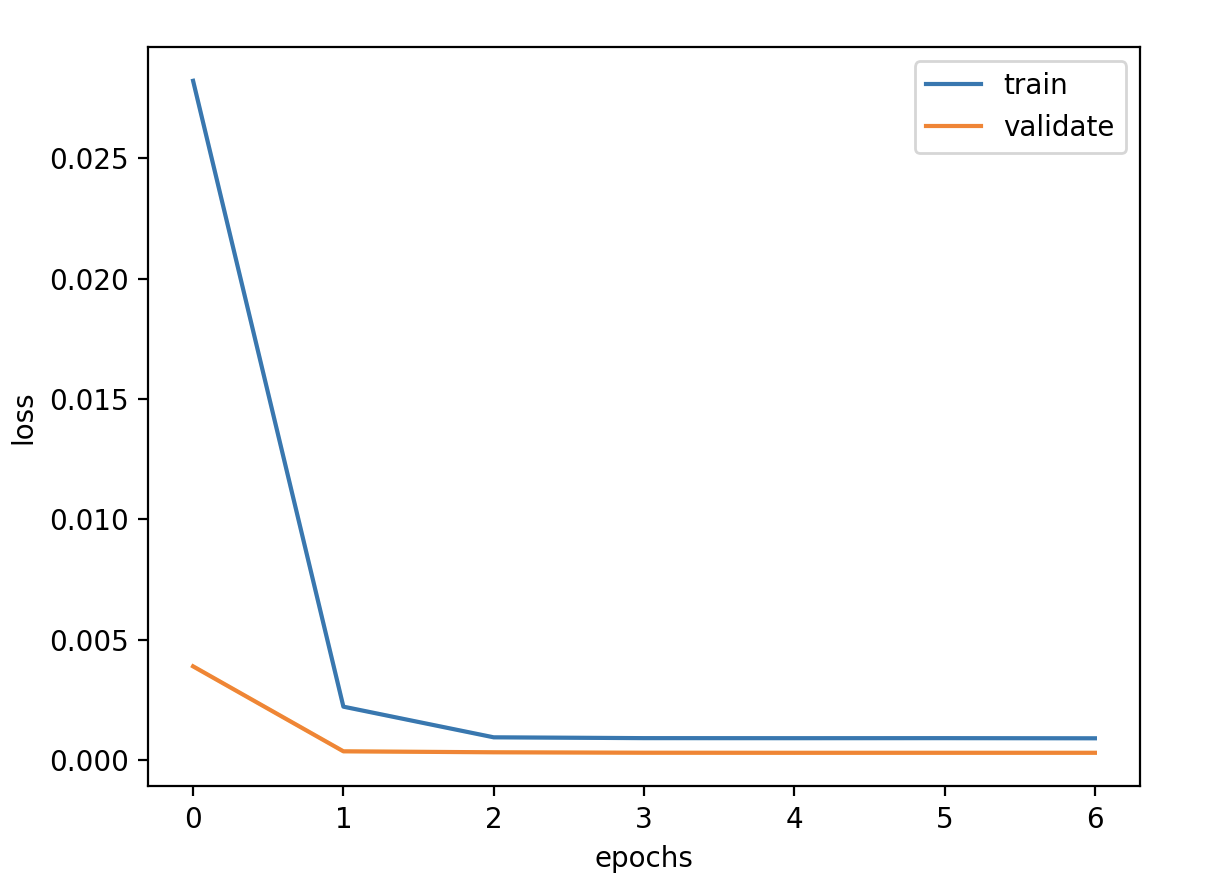
验证损失 1 2 3 4 5 6 7 8 9 validate cost: 0.0003053233659405426 elapsed time: 8.588087797164917 (s) Train Score: 2098.81 RMSE Valid Score: 1768.38 RMSE Test Score: 880.83 RMSE # stateful带来了一些改观,从理论上讲stateful会有些好处,因为我们的数据是具有自相关性的时序数据。 # 但是stateful限制训练、验证和预测必须接受以batch为单位的数据,给后面预测带来很大变动和限制,故不使用stateful。
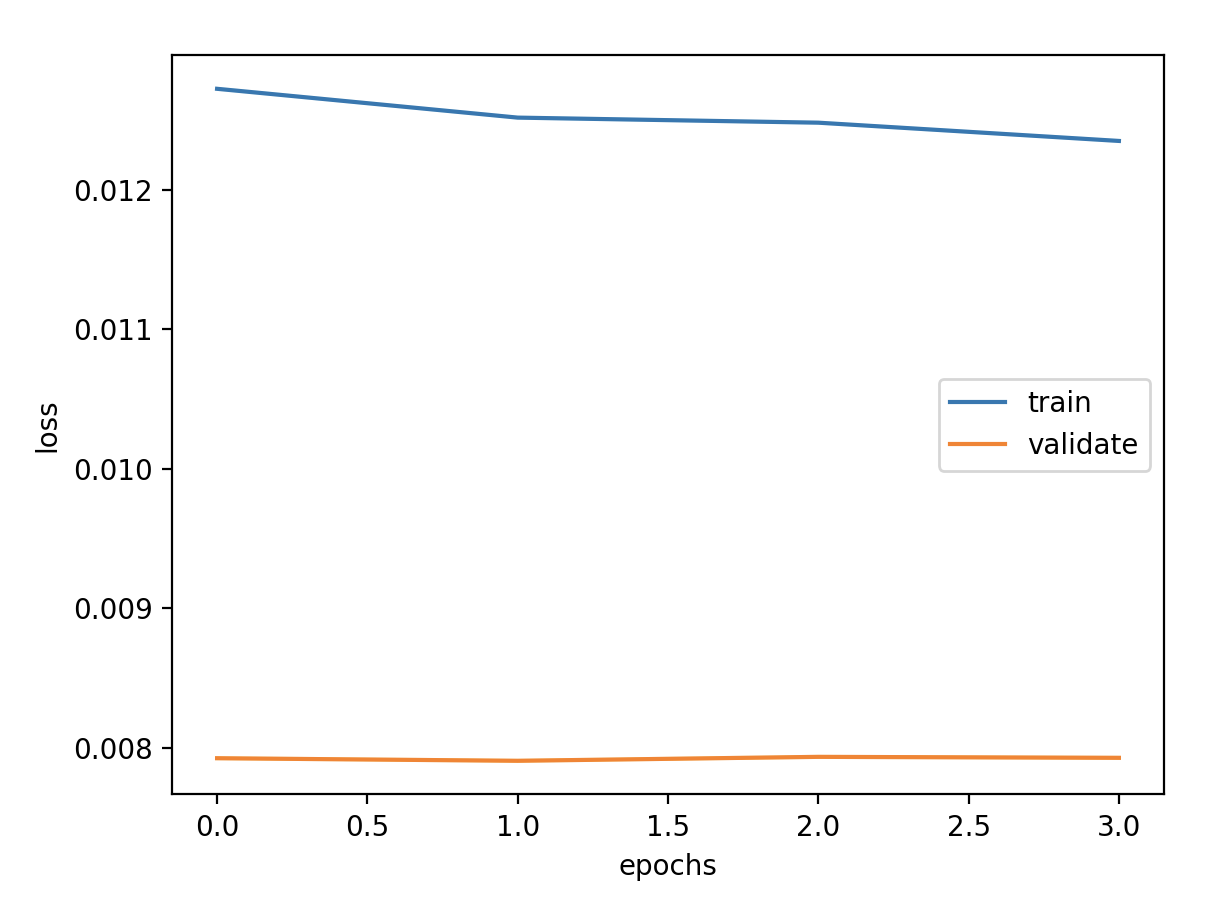
序列对数 超参数 1 2 3 4 5 6 7 8 # 定义超参数 batch_size = 128 # 批数据大小 epochs = 50 # 实验训练次数 units = 64 # 状态的输出维度 features = 1 # 最终输出维度 timesteps = 3 # 时间步长 feature_range = (0, 1) # 归一化值域 ratio = 0.8 # 数据集分割比例
模型定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 model = Sequential() model.add(LSTM(units=units, activation='tanh' , input_shape=(timesteps, features))) model.add(Dense(1 )) model.summary() callbacks = [ keras.callbacks.EarlyStopping(monitor='val_loss' , patience=2 ), keras.callbacks.ModelCheckpoint(filepath='model.h5' , monitor='val_loss' , save_best_only=True ), keras.callbacks.ReduceLROnPlateau(monitor='val_loss' , factor=0.01 , patience=2 ) ] model.compile (loss='mse' , optimizer='adam' ) history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1 , validation_data=(x_valid, y_valid), shuffle=False , callbacks=callbacks)
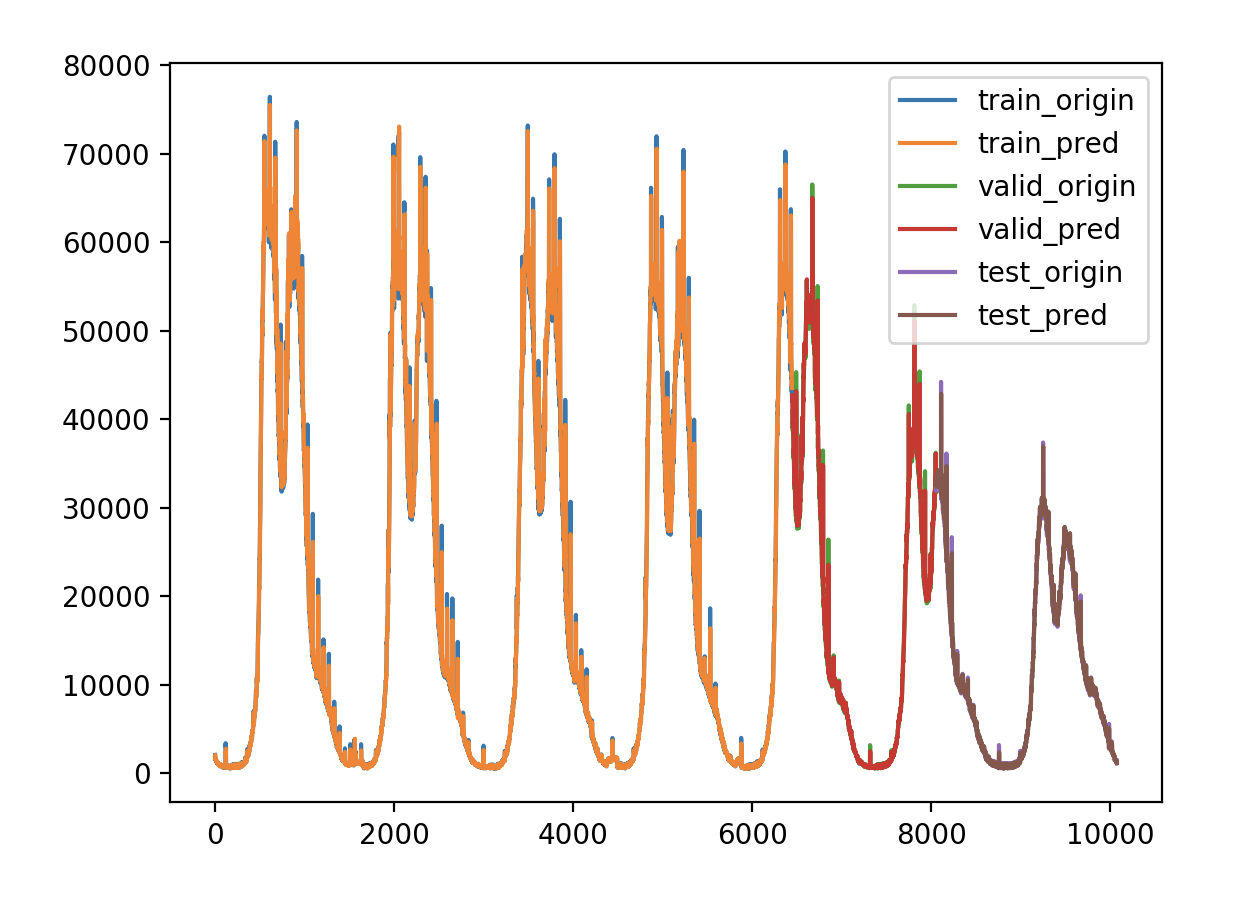
验证损失 1 2 3 4 5 6 7 validate cost: 0.0003706229881521907 elapsed time: 2.328054904937744 (s) Train Score: 2451.66 RMSE Valid Score: 1843.60 RMSE Test Score: 901.27 RMSE # 取对数在验证集和测试集上有所改观,在训练集上误差稍微增大
序列差分 超参数 1 2 3 4 5 6 7 8 # 定义超参数 batch_size = 128 # 批数据大小 epochs = 50 # 实验训练次数 units = 64 # 状态的输出维度 features = 1 # 最终输出维度 timesteps = 3 # 时间步长 feature_range = (0, 1) # 归一化值域 ratio = 0.8 # 数据集分割比例
模型定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 model = Sequential() model.add(LSTM(units=units, activation='tanh' , input_shape=(timesteps, features))) model.add(Dense(1 )) model.summary() callbacks = [ keras.callbacks.EarlyStopping(monitor='val_loss' , patience=2 ), keras.callbacks.ModelCheckpoint(filepath='model.h5' , monitor='val_loss' , save_best_only=True ), keras.callbacks.ReduceLROnPlateau(monitor='val_loss' , factor=0.01 , patience=2 ) ] model.compile (loss='mse' , optimizer='adam' ) history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1 , validation_data=(x_valid, y_valid), shuffle=False , callbacks=callbacks)
一阶差分 1 2 3 4 5 6 7 8 9 10 11 validate cost: 9.300382513113658e-05 elapsed time: 1.9793977737426758 (s) Train Score: 1868.55 RMSE Valid Score: 1608.05 RMSE Test Score: 884.86 RMSE # 一阶差分误差改善效果明显,相较于取对数更优。 # 经过验证发现将归一化值域调整为 feature_range = (-1, 1) 之后 # 验证集损失 val_loss 会增大,但是 Train, Valid, Test 的 RMSE 却减少 100-200左右 # 经过差分之后的数据有正有负,似乎 (-1, 1) 是合理的,但是本文将保持 (0, 1) 不变 # 研究其他变化带来的变化,最后选出最优的特征和超参数,归一化值域可随时更改
二阶差分 1 2 3 4 5 6 7 validate cost: 0.00017968161298761821 elapsed time: 2.5699269771575928 (s) Train Score: 2607.74 RMSE Valid Score: 2270.10 RMSE Test Score: 1025.25 RMSE # 二阶差分反而更差了,故只取一阶差分
序列对数差分 超参数 1 2 3 4 5 6 7 8 # 定义超参数 batch_size = 128 # 批数据大小 epochs = 50 # 实验训练次数 units = 64 # 状态的输出维度 features = 1 # 最终输出维度 timesteps = 3 # 时间步长 feature_range = (0, 1) # 归一化值域 ratio = 0.8 # 数据集分割比例
模型定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 model = Sequential() model.add(LSTM(units=units, activation='tanh' , input_shape=(timesteps, features))) model.add(Dense(1 )) model.summary() callbacks = [ keras.callbacks.EarlyStopping(monitor='val_loss' , patience=2 ), keras.callbacks.ModelCheckpoint(filepath='model.h5' , monitor='val_loss' , save_best_only=True ), keras.callbacks.ReduceLROnPlateau(monitor='val_loss' , factor=0.01 , patience=2 ) ] model.compile (loss='mse' , optimizer='adam' ) history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1 , validation_data=(x_valid, y_valid), shuffle=False , callbacks=callbacks)
验证损失 1 2 3 4 5 6 7 8 9 10 validate cost: 8.005627370742416e-05 elapsed time: 2.5233328342437744 (s) Train Score: 1883.97 RMSE Valid Score: 1621.68 RMSE Test Score: 879.93 RMSE # 可以发现对数差分的效果几乎和一阶差分的效果是一样的,取对数的效果微乎其微。 # 差分之后的序列更接近平稳序列,可能更有利于LSTM建模预测。 # 取对数只是缩小值域,再说还有归一化操作,似乎不是必要的。 # 比如像LightGBM算法并没有归一化操作,所以取对数有比较好的调参效果。
增加日期属性
超参数 1 2 3 4 5 6 7 8 # 定义超参数 batch_size = 128 # 批数据大小 epochs = 50 # 实验训练次数 units = 64 # 状态的输出维度 features = 4 # 最终输出维度 timesteps = 3 # 时间步长 feature_range = (0, 1) # 归一化值域 ratio = 0.8 # 数据集分割比例
模型定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 model = Sequential() model.add(LSTM(units=units, activation='tanh' , input_shape=(timesteps, features))) model.add(Dense(1 )) model.summary() callbacks = [ keras.callbacks.EarlyStopping(monitor='val_loss' , patience=2 ), keras.callbacks.ModelCheckpoint(filepath='model.h5' , monitor='val_loss' , save_best_only=True ), keras.callbacks.ReduceLROnPlateau(monitor='val_loss' , factor=0.01 , patience=2 ) ] model.compile (loss='mse' , optimizer='adam' ) history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1 , validation_data=(x_valid, y_valid), shuffle=False , callbacks=callbacks)
验证损失 1 2 3 4 5 6 7 validate cost: 0.002384760812697476 elapsed time: 1.893902063369751 (s) Train Score: 2104.13 RMSE Valid Score: 5434.98 RMSE Test Score: 5839.40 RMSE # 模型在训练集、验证集和测试集表现越来越差
增加增长率
超参数 1 2 3 4 5 6 7 8 # 定义超参数 batch_size = 128 # 批数据大小 epochs = 50 # 实验训练次数 units = 64 # 状态的输出维度 features = 2 # 最终输出维度 timesteps = 3 # 时间步长 feature_range = (0, 1) # 归一化值域 ratio = 0.8 # 数据集分割比例
模型定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 model = Sequential() model.add(LSTM(units=units, activation='tanh' , input_shape=(timesteps, features))) model.add(Dense(1 )) model.summary() callbacks = [ keras.callbacks.EarlyStopping(monitor='val_loss' , patience=2 ), keras.callbacks.ModelCheckpoint(filepath='model.h5' , monitor='val_loss' , save_best_only=True ), keras.callbacks.ReduceLROnPlateau(monitor='val_loss' , factor=0.01 , patience=2 ) ] model.compile (loss='mse' , optimizer='adam' ) history = model.fit(x_train, y_train, batch_size=batch_size, epochs=1 , verbose=1 , validation_data=(x_valid, y_valid), shuffle=False , callbacks=callbacks)
验证损失 1 2 3 4 5 6 7 8 9 10 11 validate cost: 0.00023447876570476951 elapsed time: 2.060291051864624 (s) Train Score: 2084.47 RMSE Valid Score: 1704.23 RMSE Test Score: 1039.05 RMSE # 增长率也可以改善预测结果,原理和一阶差分相似,差分是做减法,增长率是做除法。 # 误差减小了,但是增长率产生了负数的情况。 # 之前的实验是增长率结合stateful LSTM,得到的结果是:增长率可以和一阶差分类似改善拟合结果,并无发现有负数的情况。 # 做完实验考虑预测部分的时候发现stateful必须接受batch为单位的数据,使得预测变得麻烦,改动工作较大。
预测增长率 变换目标值为增长率,预测增长率,和前一天的交易量进行计算,得到当前的交易预测值。
1 2 3 4 5 6 7 8 9 validate cost: 0.007923171162502511 elapsed time: 1.5544190406799316 (s) Train Score: 1575.60 RMSE Valid Score: 1307.57 RMSE Test Score: 761.17 RMSE # 结合图可以看出,相比增加增长率这个特征,直接预测增长率收到了比较好的效果。 # 而且没有出现负数的情况,拟合误差减少很多,可以采用。
双层LSTM 超参数 1 2 3 4 5 6 7 8 # 定义超参数 batch_size = 128 # 批数据大小 epochs = 50 # 实验训练次数 units = 64 # 状态的输出维度 features = 1 # 最终输出维度 timesteps = 3 # 时间步长 feature_range = (0, 1) # 归一化值域 ratio = 0.8 # 数据集分割比例
单层LSTM有Dropout 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 model = Sequential() model.add(LSTM(units=units, activation='tanh' , input_shape=(timesteps, features))) model.add(Dropout(0.2 )) model.add(Dense(1 )) model.summary() callbacks = [ keras.callbacks.EarlyStopping(monitor='val_loss' , patience=2 ), keras.callbacks.ModelCheckpoint(filepath='model.h5' , monitor='val_loss' , save_best_only=True ), keras.callbacks.ReduceLROnPlateau(monitor='val_loss' , factor=0.01 , patience=2 ) ] model.compile (loss='mse' , optimizer='adam' ) history = model.fit(x_train, y_train, batch_size=batch_size, epochs=1 , verbose=1 , validation_data=(x_valid, y_valid), shuffle=False , callbacks=callbacks)
1 2 3 4 5 6 validate cost: 0.00024637159007593934 elapsed time: 2.1154732704162598 (s) Train Score: 2107.65 RMSE Valid Score: 1746.91 RMSE Test Score: 906.77 RMSE
双层LSTM有Dropout 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 model = Sequential() model.add(LSTM(units=units, activation='tanh' , input_shape=(timesteps, features), return_sequences=True )) model.add(Dropout(0.2 )) model.add(LSTM(units=units, activation='tanh' , input_shape=(timesteps, features))) model.add(Dropout(0.2 )) model.add(Dense(1 )) model.summary() callbacks = [ keras.callbacks.EarlyStopping(monitor='val_loss' , patience=2 ), keras.callbacks.ModelCheckpoint(filepath='model.h5' , monitor='val_loss' , save_best_only=True ), keras.callbacks.ReduceLROnPlateau(monitor='val_loss' , factor=0.01 , patience=2 ) ] model.compile (loss='mse' , optimizer='adam' ) history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1 , validation_data=(x_valid, y_valid), shuffle=False , callbacks=callbacks)
1 2 3 4 5 6 validate cost: 0.00030157841621581707 elapsed time: 3.7397210597991943 (s) Train Score: 2266.96 RMSE Valid Score: 1932.75 RMSE Test Score: 1101.70 RMSE
双层LSTM无Dropout 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 model = Sequential() model.add(LSTM(units=units, activation='tanh' , input_shape=(timesteps, features), return_sequences=True )) model.add(LSTM(units=units, activation='tanh' , input_shape=(timesteps, features))) model.add(Dense(1 )) model.summary() callbacks = [ keras.callbacks.EarlyStopping(monitor='val_loss' , patience=2 ), keras.callbacks.ModelCheckpoint(filepath='model.h5' , monitor='val_loss' , save_best_only=True ), keras.callbacks.ReduceLROnPlateau(monitor='val_loss' , factor=0.01 , patience=2 ) ] model.compile (loss='mse' , optimizer='adam' ) history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1 , validation_data=(x_valid, y_valid), shuffle=False , callbacks=callbacks)
1 2 3 4 5 6 7 8 9 validate cost: 0.00028111153606354833 elapsed time: 3.16672682762146 (s) Train Score: 2269.73 RMSE Valid Score: 1866.01 RMSE Test Score: 1003.38 RMSE # 单层LSTM加上Dropout正则化层,相较于单层LSTM似乎有所改善,但对于Dropout的作用还不太明白。 # 双层LSTM加上Dropout正则化层,相较于双层LSTM又是略差些,但是相差不大。 # 对于这些结果,可能需要多次实验取均值来确定哪些因素对拟合更优。
差分结合增长率 在一阶差分的基础上增加增长率这个特征
超参数 1 2 3 4 5 6 7 8 # 定义超参数 batch_size = 128 # 批数据大小 epochs = 50 # 实验训练次数 units = 64 # 状态的输出维度 features = 2 # 最终输出维度 timesteps = 3 # 时间步长 feature_range = (0, 1) # 归一化值域 ratio = 0.8 # 数据集分割比例
模型定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 model = Sequential() model.add(LSTM(units=units, activation='tanh' , input_shape=(timesteps, features))) model.add(Dense(1 )) model.summary() callbacks = [ keras.callbacks.EarlyStopping(monitor='val_loss' , patience=2 ), keras.callbacks.ModelCheckpoint(filepath='model.h5' , monitor='val_loss' , save_best_only=True ), keras.callbacks.ReduceLROnPlateau(monitor='val_loss' , factor=0.01 , patience=2 ) ] model.compile (loss='mse' , optimizer='adam' ) history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1 , validation_data=(x_valid, y_valid), shuffle=False , callbacks=callbacks)
验证损失 1 2 3 4 5 6 7 8 9 10 validate cost: 8.446127437506554e-05 elapsed time: 2.3685760498046875 (s) Train Score: 1787.02 RMSE Valid Score: 1532.42 RMSE Test Score: 901.20 RMSE # 从误差结果可以看出,这个和一阶差分的结果相差无几 # 但是从拟合图上看,拟合值出现了负数的情况,这是增长率带来的结果 # 所以可以通过预测增长率,再结合一阶差分看看
预测增长率 预测增长率,再结合一阶差分,这个和上面的不同之处在于使用增长率作为目标值。
1 2 3 4 5 6 7 8 validate cost: 0.007926768652017368 elapsed time: 1.7802140712738037 (s) Train Score: 1600.33 RMSE Valid Score: 1325.91 RMSE Test Score: 769.42 RMSE # 这个结果和单纯预测增长率的结果又是相差无几,差不差分都无所谓了。 # 总结:一阶差分和预测增长率是二选一的结果,二者都能达到较好的优化,预测增长率更优一些。
Bidirectional LSTM
On some sequence prediction problems, it can be beneficial to allow the LSTM model to learn the input sequence both forward and backwards and concatenate both interpretations.Bidirectional LSTM
超参数 1 2 3 4 5 6 7 8 # 定义超参数 batch_size = 128 # 批数据大小 epochs = 50 # 实验训练次数 units = 64 # 状态的输出维度 features = 1 # 最终输出维度 timesteps = 3 # 时间步长 feature_range = (0, 1) # 归一化值域 ratio = 0.8 # 数据集分割比例
模型定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 model = Sequential() model.add(Bidirectional(LSTM(units=units, activation='tanh' ), input_shape=(timesteps, features))) model.add(Dense(1 )) model.summary() callbacks = [ keras.callbacks.EarlyStopping(monitor='val_loss' , patience=2 ), keras.callbacks.ModelCheckpoint(filepath='model.h5' , monitor='val_loss' , save_best_only=True ), keras.callbacks.ReduceLROnPlateau(monitor='val_loss' , factor=0.01 , patience=2 ) ] model.compile (loss='mse' , optimizer='adam' ) history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1 , validation_data=(x_valid, y_valid), shuffle=False , callbacks=callbacks)
验证损失 1 2 3 4 5 6 7 validate cost: 0.0002106719806980023 elapsed time: 2.6818039417266846 (s) Train Score: 1946.72 RMSE Valid Score: 1615.40 RMSE Test Score: 823.85 RMSE # Bidirectional LSTM 具有明显改善效果,这个可以结合一阶差分或者预测增长率使用。
CNN LSTM
A convolutional neural network, or CNN for short, is a type of neural network developed for working with two-dimensional image data.This hybrid model is called a CNN-LSTM .
超参数 1 2 3 4 5 6 7 8 # 定义超参数 batch_size = 128 # 批数据大小 epochs = 50 # 实验训练次数 units = 64 # 状态的输出维度 features = 1 # 最终输出维度 timesteps = 4 # 时间步长 feature_range = (0, 1) # 归一化值域 ratio = 0.8 # 数据集分割比例
模型定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 model = Sequential() model.add(TimeDistributed(Conv1D(filters=units, kernel_size=1 , activation='tanh' ), input_shape=(None , timesteps//2 , features))) model.add(TimeDistributed(MaxPooling1D(pool_size=2 ))) model.add(TimeDistributed(Flatten())) model.add(LSTM(units=units, activation='tanh' )) model.add(Dense(1 )) model.summary() callbacks = [ keras.callbacks.EarlyStopping(monitor='val_loss' , patience=2 ), keras.callbacks.ModelCheckpoint(filepath='model.h5' , monitor='val_loss' , save_best_only=True ), keras.callbacks.ReduceLROnPlateau(monitor='val_loss' , factor=0.01 , patience=2 ) ] model.compile (loss='mse' , optimizer='adam' ) history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1 , validation_data=(x_valid, y_valid), shuffle=False , callbacks=callbacks)
验证损失 1 2 3 4 5 6 validate cost: 0.00021777707989074557 elapsed time: 2.1609442234039307 (s) Train Score: 2035.46 RMSE Valid Score: 1642.41 RMSE Test Score: 851.72 RMSE
ConvLSTM
A type of LSTM related to the CNN-LSTM is the ConvLSTM, where the convolutional reading of input is built directly into each LSTM unit.
超参数 1 2 3 4 5 6 7 8 # 定义超参数 batch_size = 128 # 批数据大小 epochs = 50 # 实验训练次数 units = 64 # 状态的输出维度 features = 1 # 最终输出维度 timesteps = 4 # 时间步长 feature_range = (0, 1) # 归一化值域 ratio = 0.8 # 数据集分割比例
模型定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 model = Sequential() model.add(ConvLSTM2D(filters=units, kernel_size=(1 ,2 ), activation='tanh' , input_shape=(timesteps//2 , 1 , timesteps//2 , features))) model.add(Flatten()) model.add(Dense(1 )) model.summary() callbacks = [ keras.callbacks.EarlyStopping(monitor='val_loss' , patience=2 ), keras.callbacks.ModelCheckpoint(filepath='model.h5' , monitor='val_loss' , save_best_only=True ), keras.callbacks.ReduceLROnPlateau(monitor='val_loss' , factor=0.01 , patience=2 ) ] model.compile (loss='mse' , optimizer='adam' ) history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1 , validation_data=(x_valid, y_valid), shuffle=False , callbacks=callbacks)
验证损失 1 2 3 4 5 6 7 8 validate cost: 0.00022352560738618104 elapsed time: 3.2140681743621826 (s) Train Score: 2092.71 RMSE Valid Score: 1663.95 RMSE Test Score: 844.92 RMSE # 三种模型相较于原始的单层 stateless LSTM 模型都具有改善效果 # Bidirectional LSTM 略好一点
优化方案 Stateless LSTM or Bidirectional LSTM or CNN LSTM or ConvLSTM
一阶差分 or 预测增长率
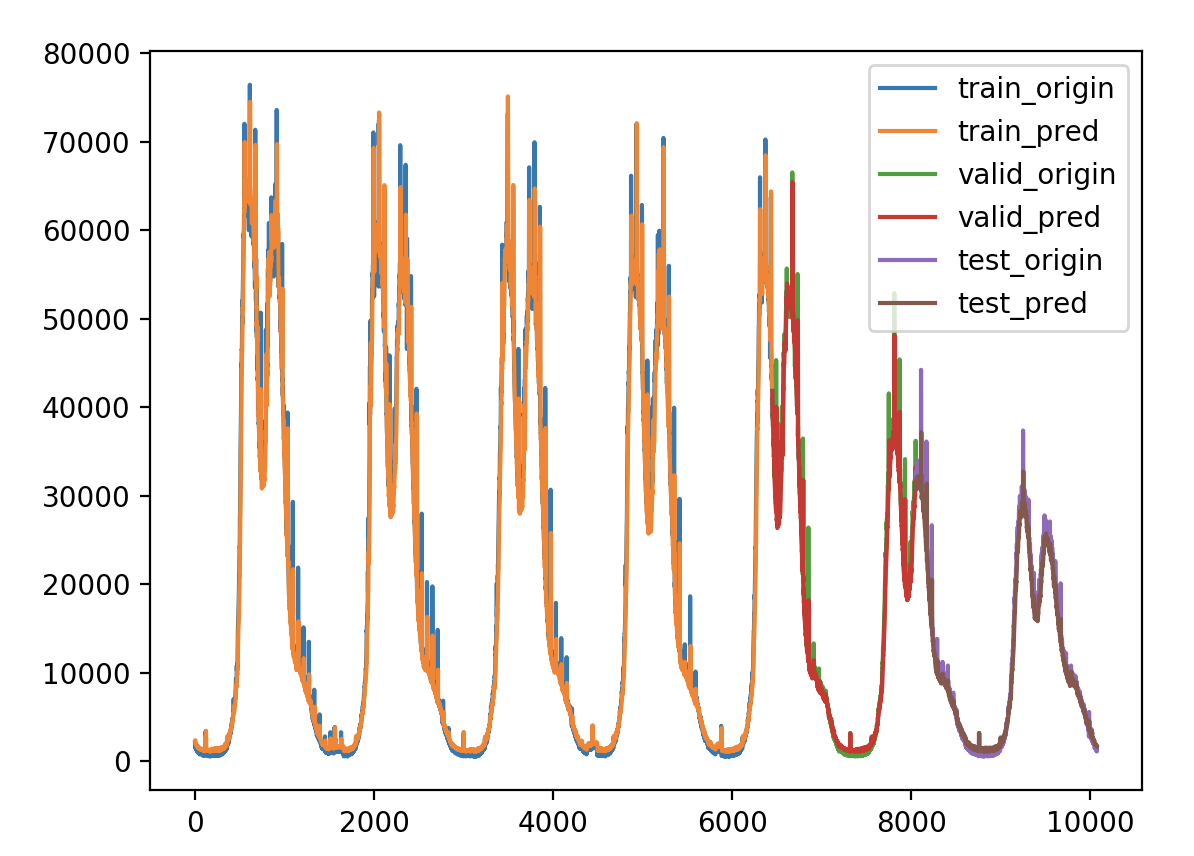
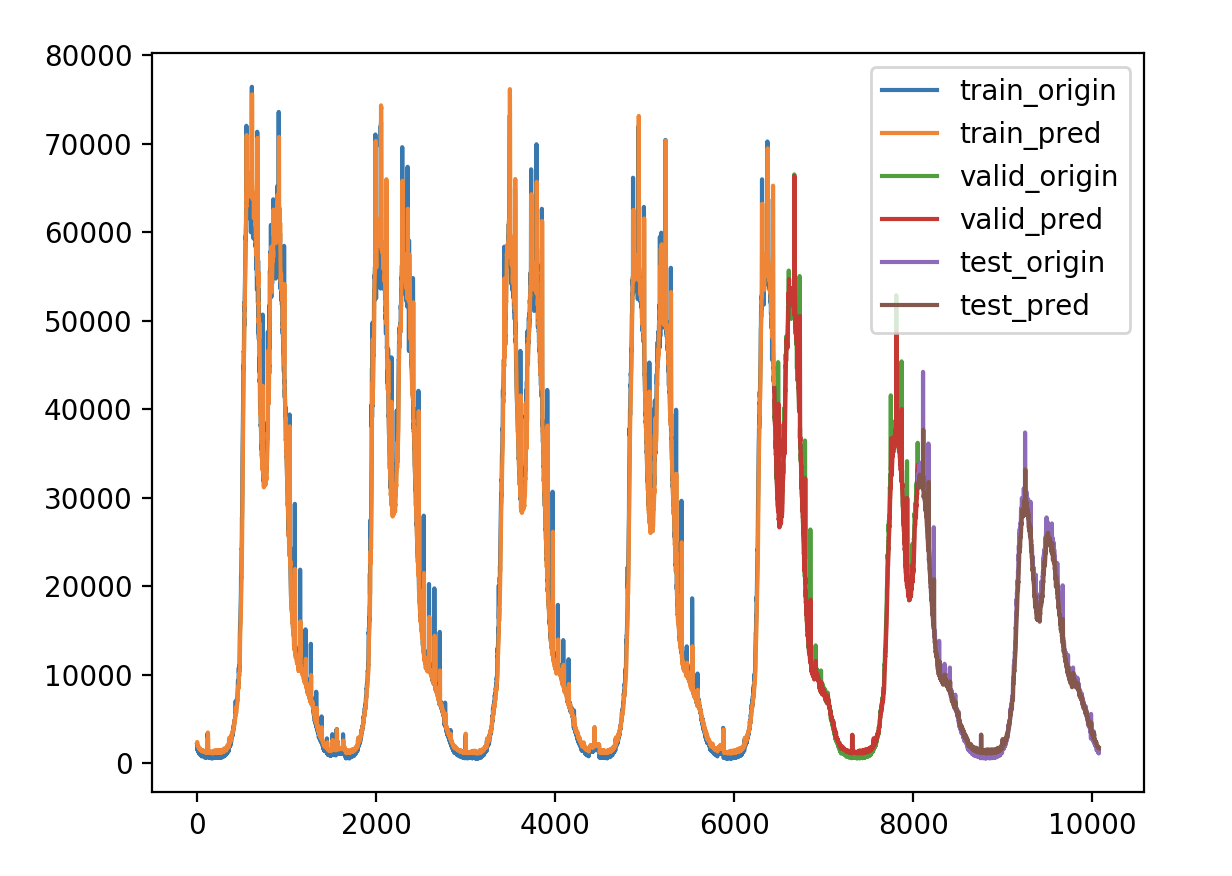
本次实验使用颜色标记的方案
超参数 1 2 3 4 5 6 7 8 # 定义超参数 batch_size = 128 # 批数据大小 epochs = 50 # 实验训练次数 units = 64 # 状态的输出维度 features = 1 # 最终输出维度 timesteps = 3 # 时间步长 feature_range = (0, 1) # 归一化值域 ratio = 0.8 # 数据集分割比例
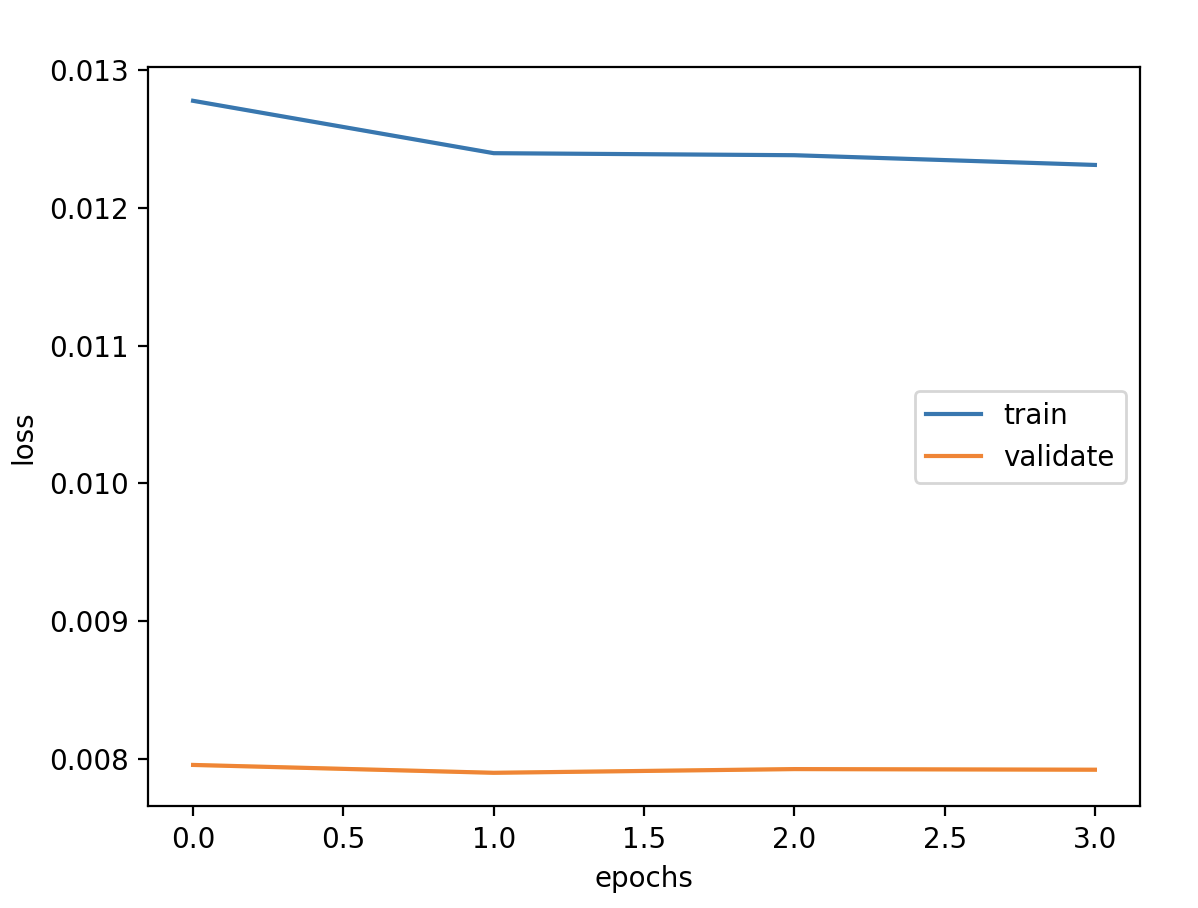
模型定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 model = Sequential() model.add(Bidirectional(LSTM(units=units, activation='tanh' ), input_shape=(timesteps, features))) model.add(Dense(1 )) model.summary() callbacks = [ keras.callbacks.EarlyStopping(monitor='val_loss' , patience=2 ), keras.callbacks.ModelCheckpoint(filepath='model.h5' , monitor='val_loss' , save_best_only=True ), keras.callbacks.ReduceLROnPlateau(monitor='val_loss' , factor=0.01 , patience=2 ) ] model.compile (loss='mse' , optimizer='adam' ) history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1 , validation_data=(x_valid, y_valid), shuffle=False , callbacks=callbacks)
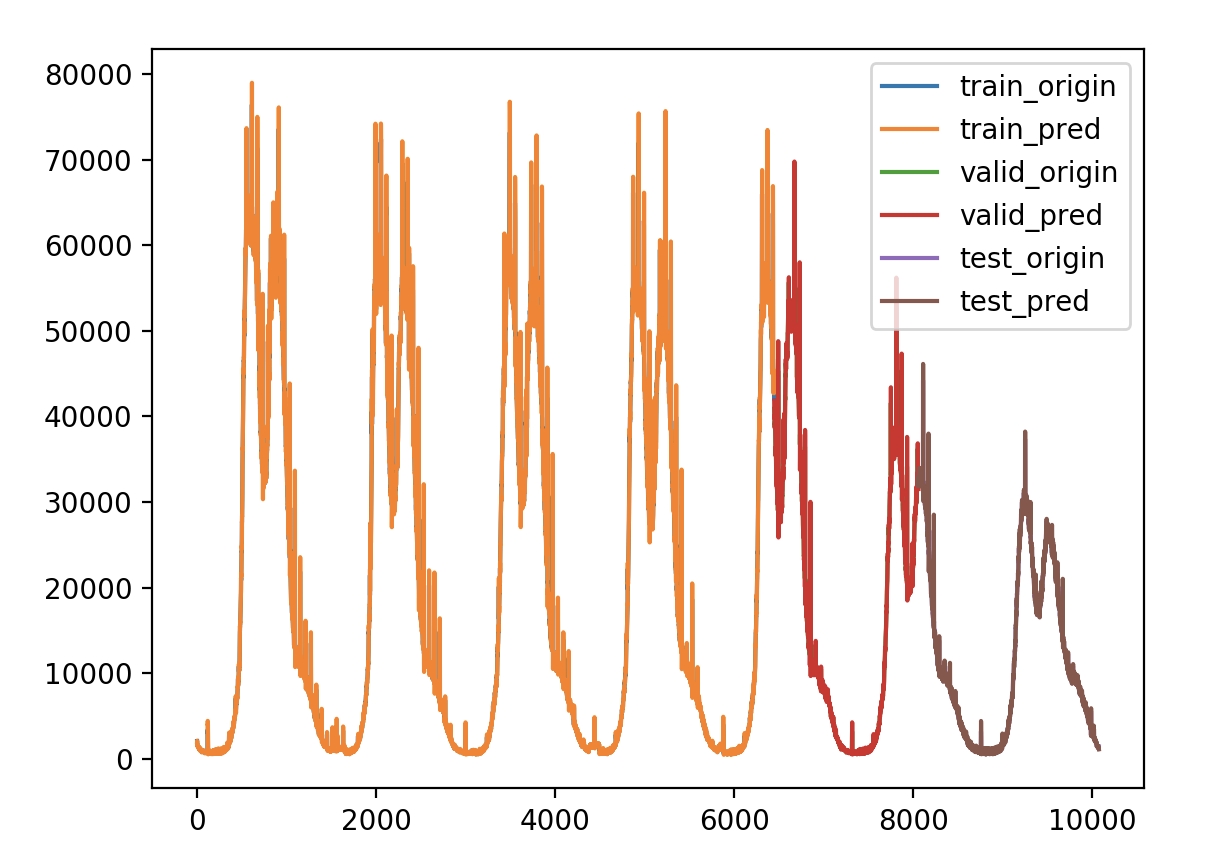
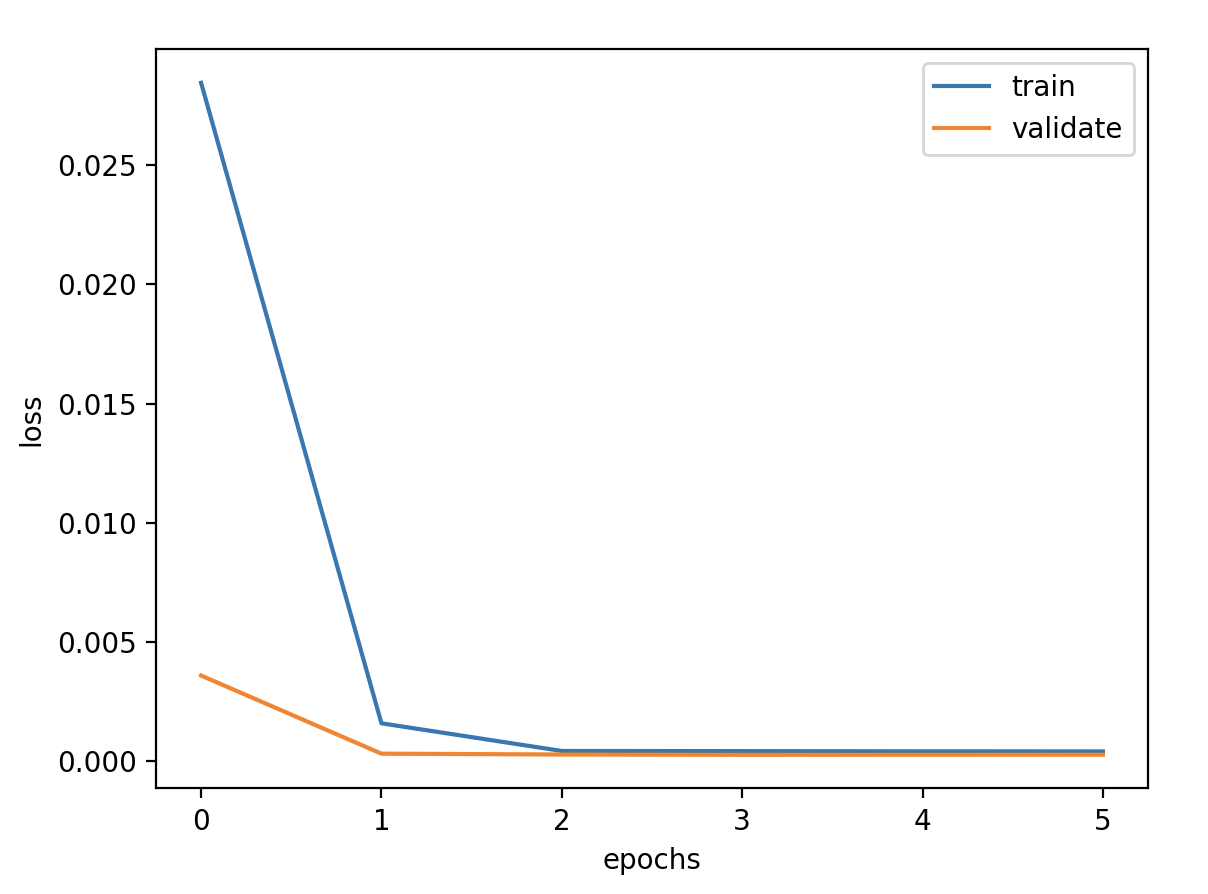
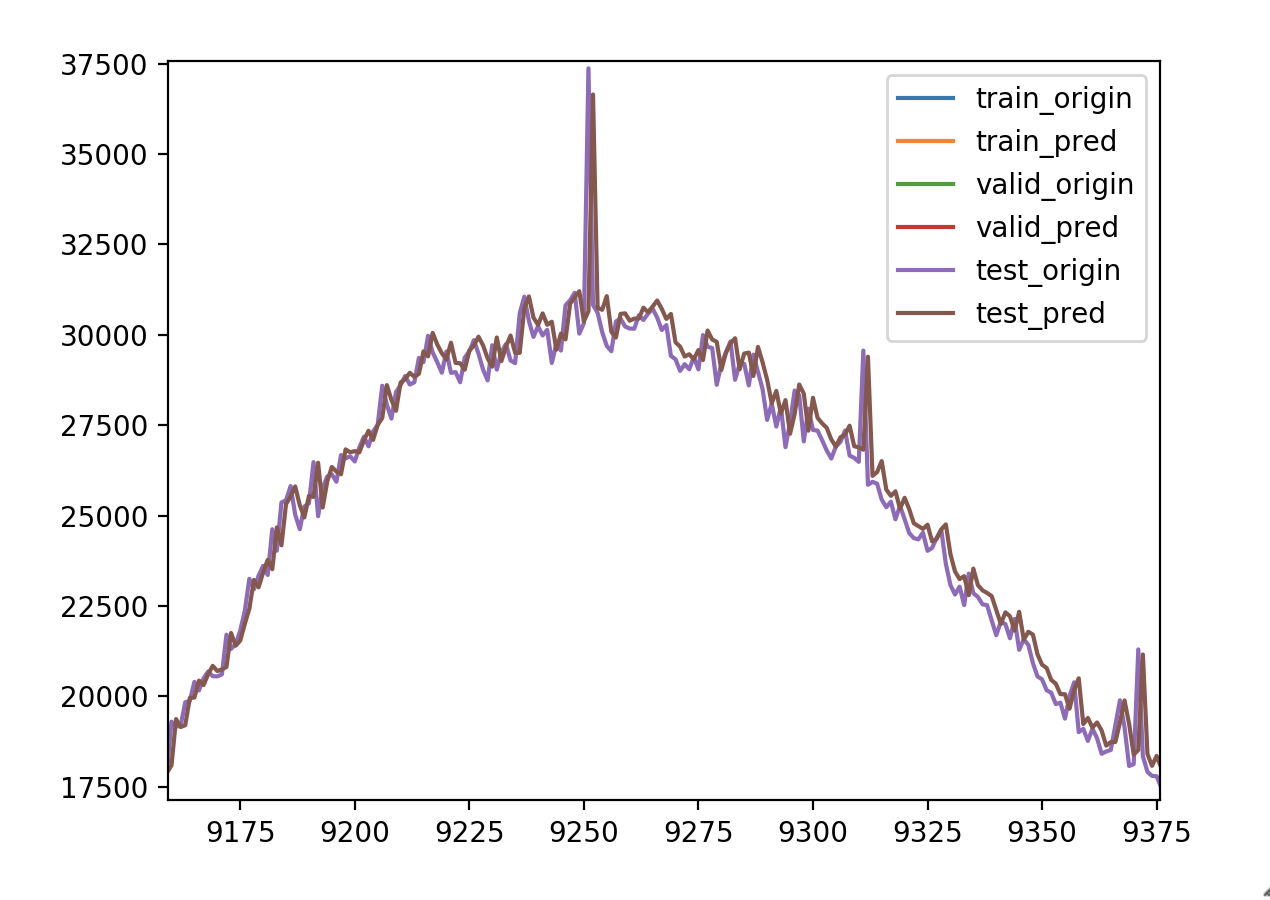
验证损失 1 2 3 4 5 6 7 8 9 validate cost: 0.00794555525360681 elapsed time: 2.404299020767212 (s) Train Score: 1576.97 RMSE Valid Score: 1307.11 RMSE Test Score: 758.50 RMSE # 可以看出这个方案和预测增长率的方案的结果是一样的,改变为Bidirectional LSTM 结构有略微的好处 # 这种双向循环神经网络的隐藏层保存了两个值,A 参与正向计算, A' 参与反向计算,最终的输出值 y 取决于 A 和 A'
看看细节
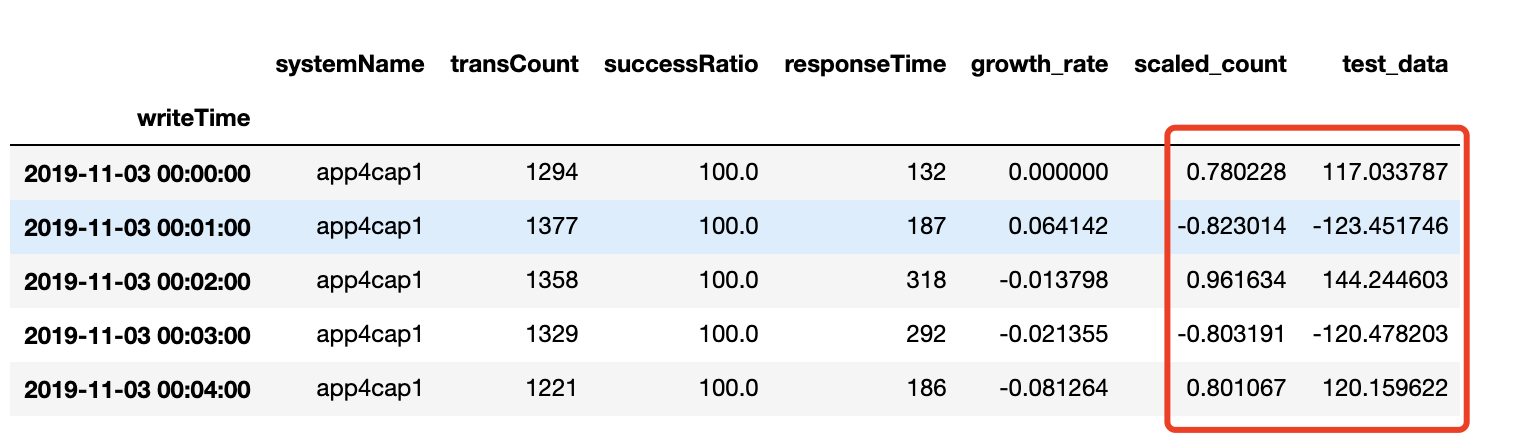
成功率 1 2 3 4 5 6 validate cost: 6.0617386995090114e-09 elapsed time: 3.4173359870910645 (s) Train Score: 0.05 RMSE Valid Score: 0.01 RMSE Test Score: 0.13 RMSE
响应时间 1 2 3 4 5 6 validate cost: 0.009244604190229511 elapsed time: 3.7244749069213867 (s) Train Score: 56.79 RMSE Valid Score: 14.35 RMSE Test Score: 77.87 RMSE
新的问题 Github上有人给出的一种解释是:这是由于序列存在自相关性
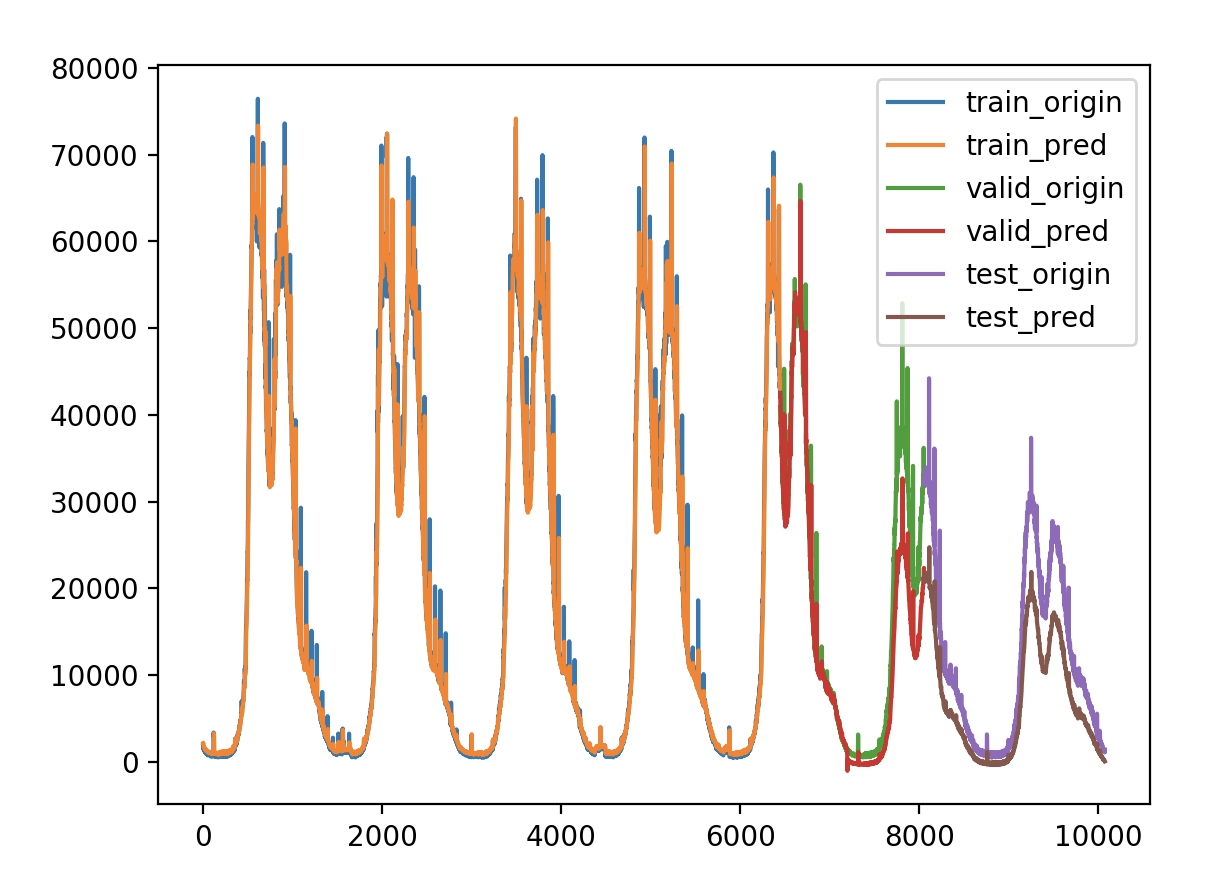
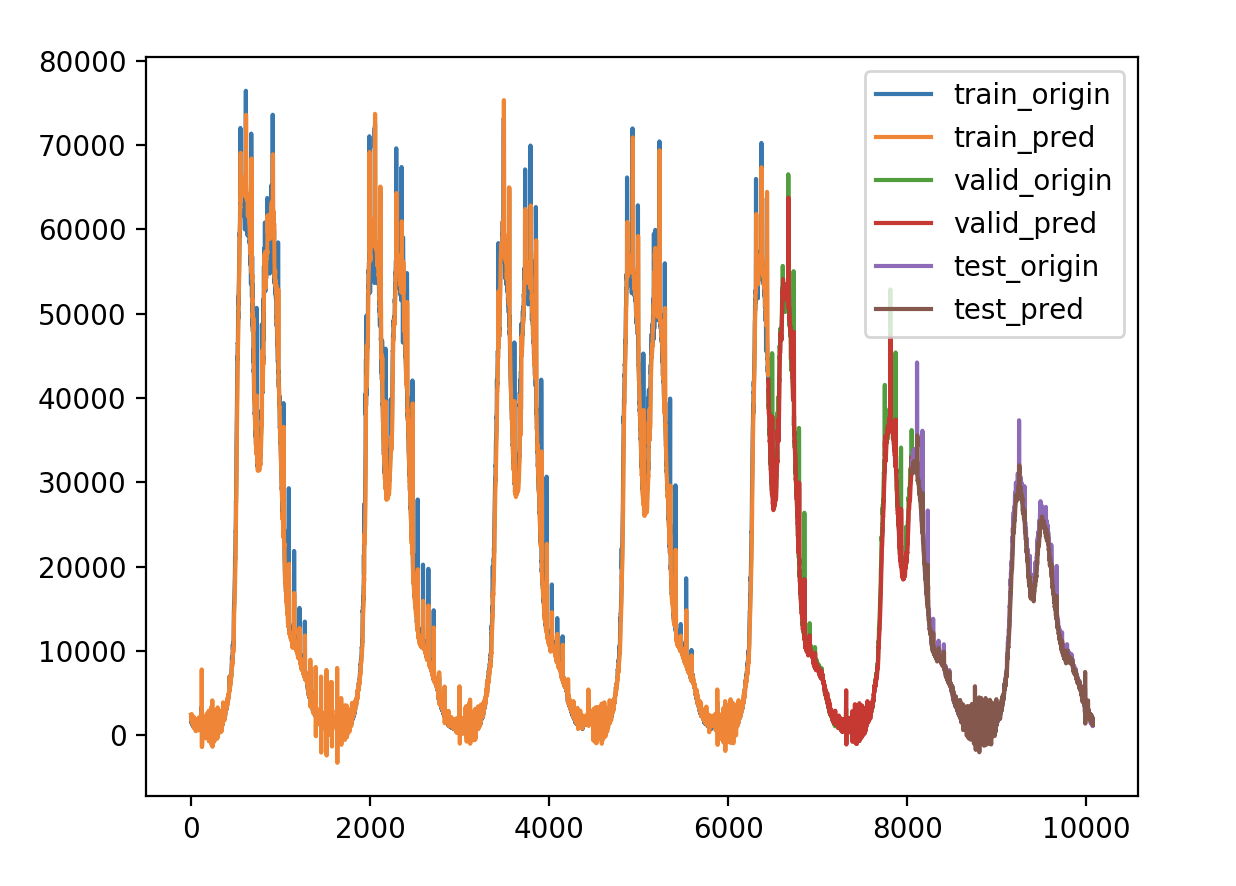
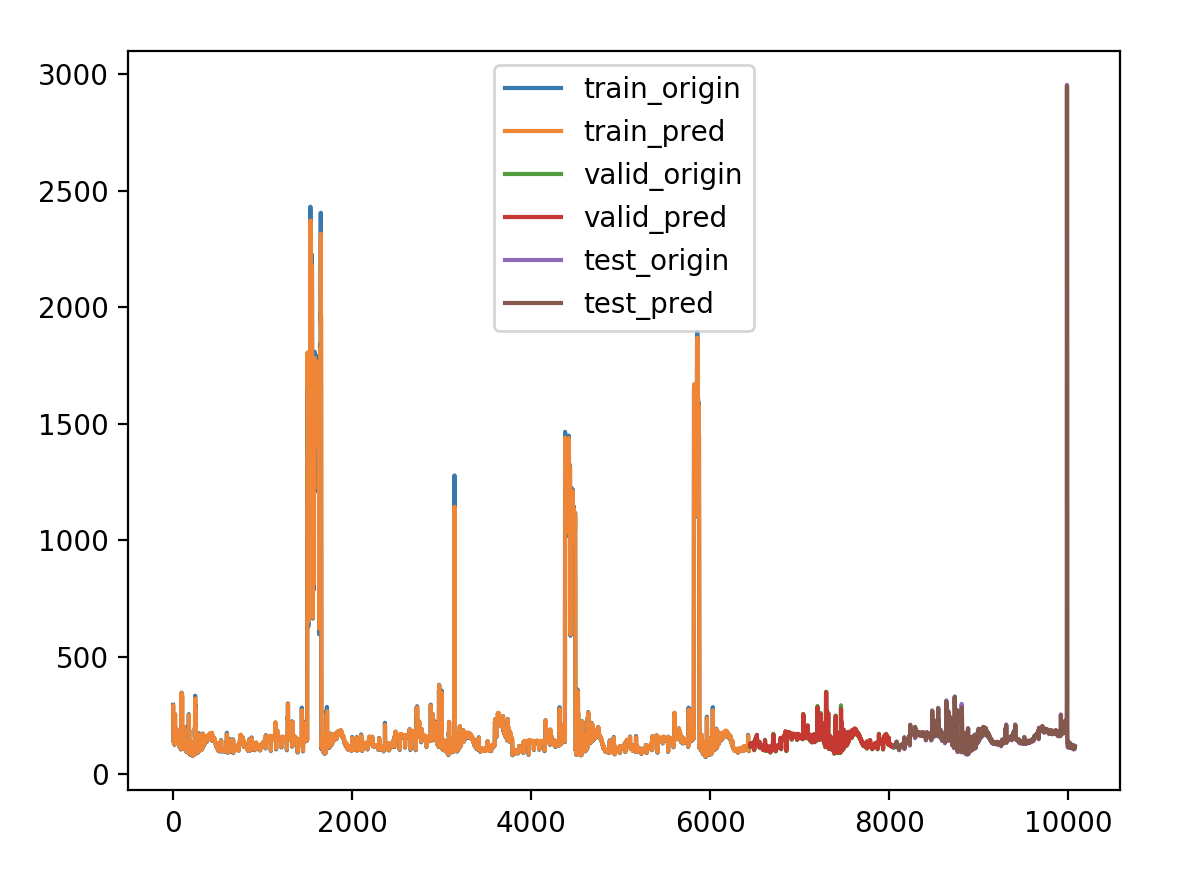
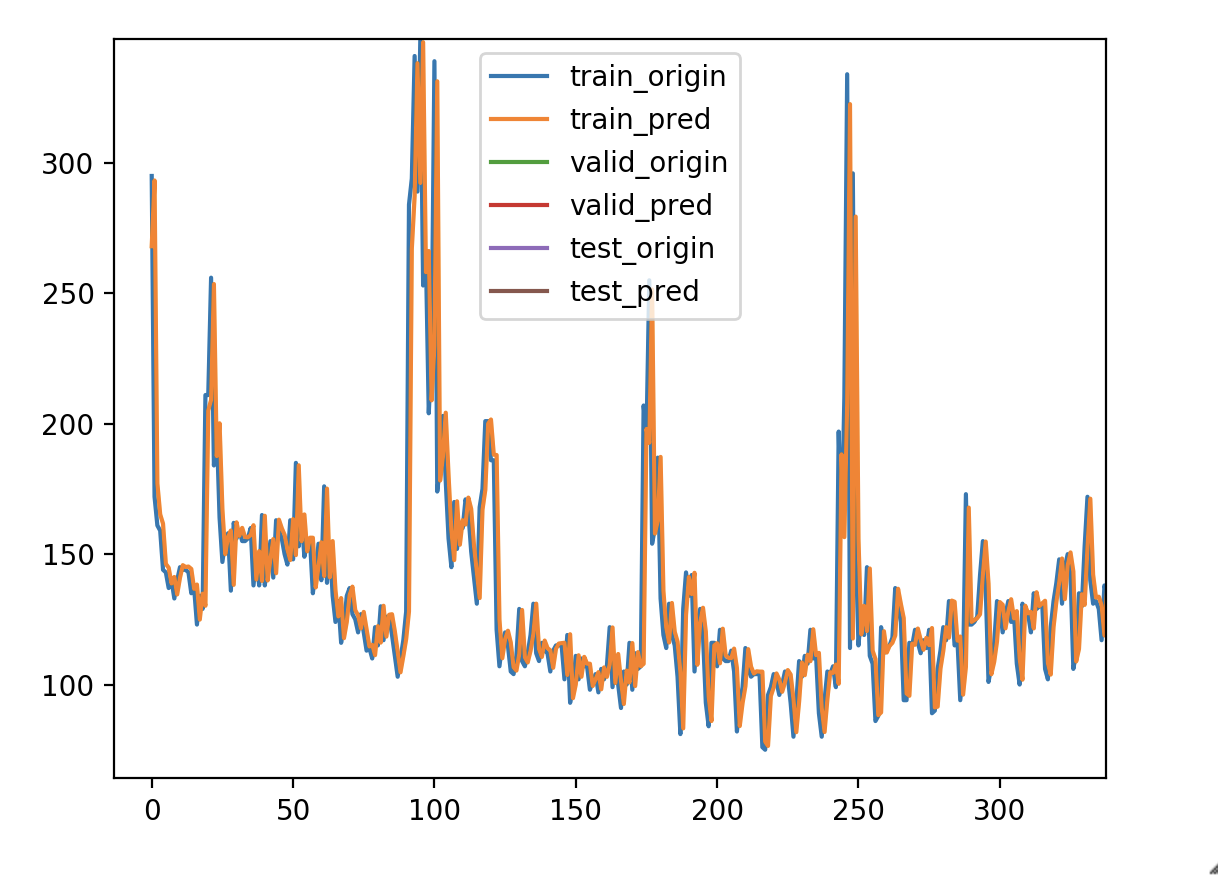
做过时间序列的朋友可能常常会有这样的感受,用了某种算法做出来的测试集的平均绝对误差率或者r2系数都很好,但是把测试集的真实值及预测值画出来对比一下,就会发现t时刻的预测值往往是t-1时刻的真实值,也就是模型倾向于把上一时刻的真实值作为下一时刻的预测值,导致两条曲线存在滞后性,也就是真实值曲线滞后于预测值曲线,就像下图右边所显示的那样。之所以会这样,是因为序列存在自相关性,如一阶自相关指的是当前时刻的值与其自身前一时刻值之间的相关性。因此,如果一个序列存在一阶自相关,模型学到的就是一阶相关性。而消除自相关性的办法就是进行差分运算,也就是我们可以将当前时刻与前一时刻的差值作为我们的回归目标
简单的说就是特征值X包含了目标值Y,试试改为一阶差分结果作为Y,上面已经试过增长率作为Y了,结果就是误差还好,但是有负数的情况出现。
如何解决 存在预测滞后的现象是因为时间序列本身存在自相关性,因为损失函数是mse,模型倾向于把上一个时刻的值当作下一个时刻的预测值,导致图形画出来看似很好,mse也很小。解决办法是消除时间序列的自相关性,可以进行差分或者分解,分解方法有EMD分解和小波分解法,上面试过差分似乎还是存在预测值滞后的问题,试过使用EMD分解一周的响应时间,性能不好,效率不高,耗时很久,效果还挺好,分解出了27个IMF分量。另外我需要证明LSTM在预测非平稳时间序列,也就是不存在自相关性的时间序列上,不存在预测值滞后的问题,我想最简单的就是构造一个一正一负的时间序列,如果LSTM模型总是拿上一个时刻的值当作下一个时刻的预测值,那么这个模型预测可以说总是错的,如果结果还好,不存在滞后问题,那么就可以使用EMD分解法来逐个预测,最后综合各个的预测结果,还有一个问题是EMD分解性能的问题,可能需要再找一个效率更高的包,可能存在也可能不存在。如果顺利的话,最后预测也是个问题,既然分解了,那么预测的时候怎么预测?
基于EMD分解与LSTM的空气质量预测
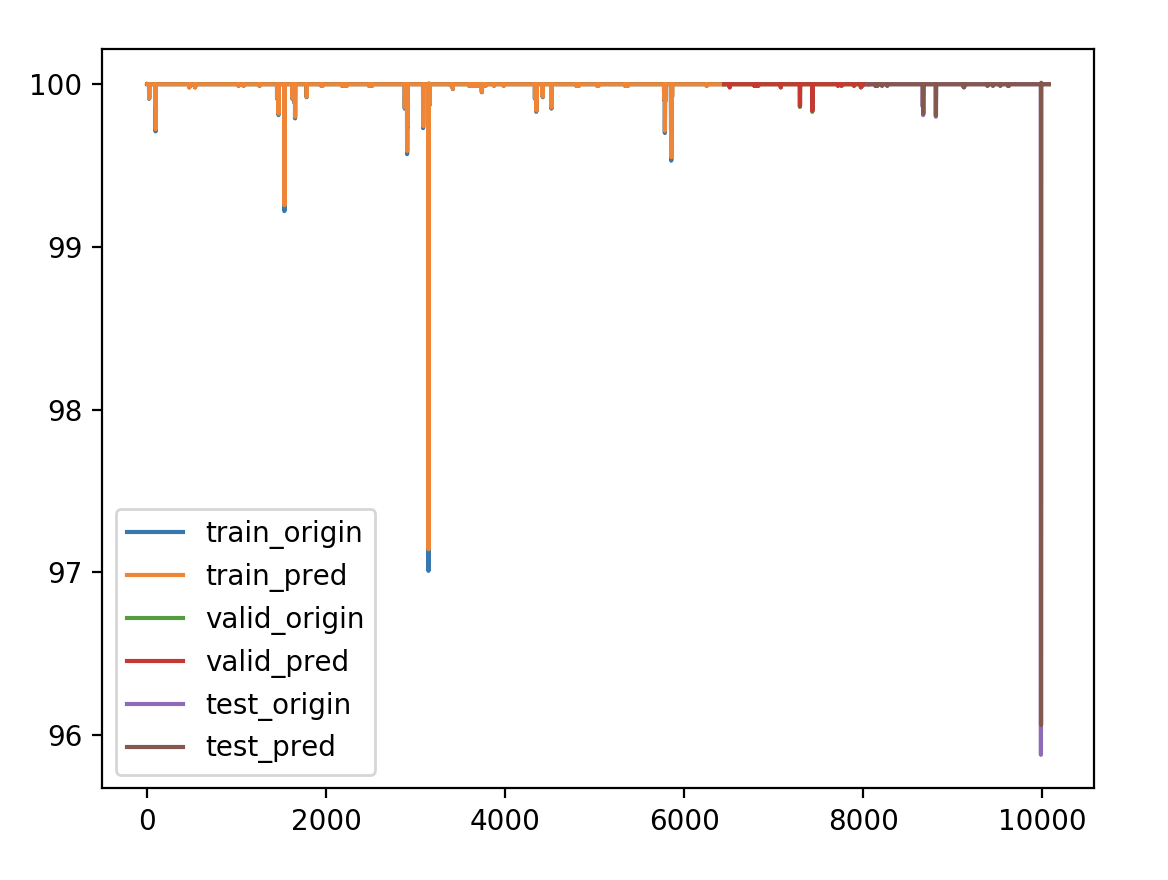
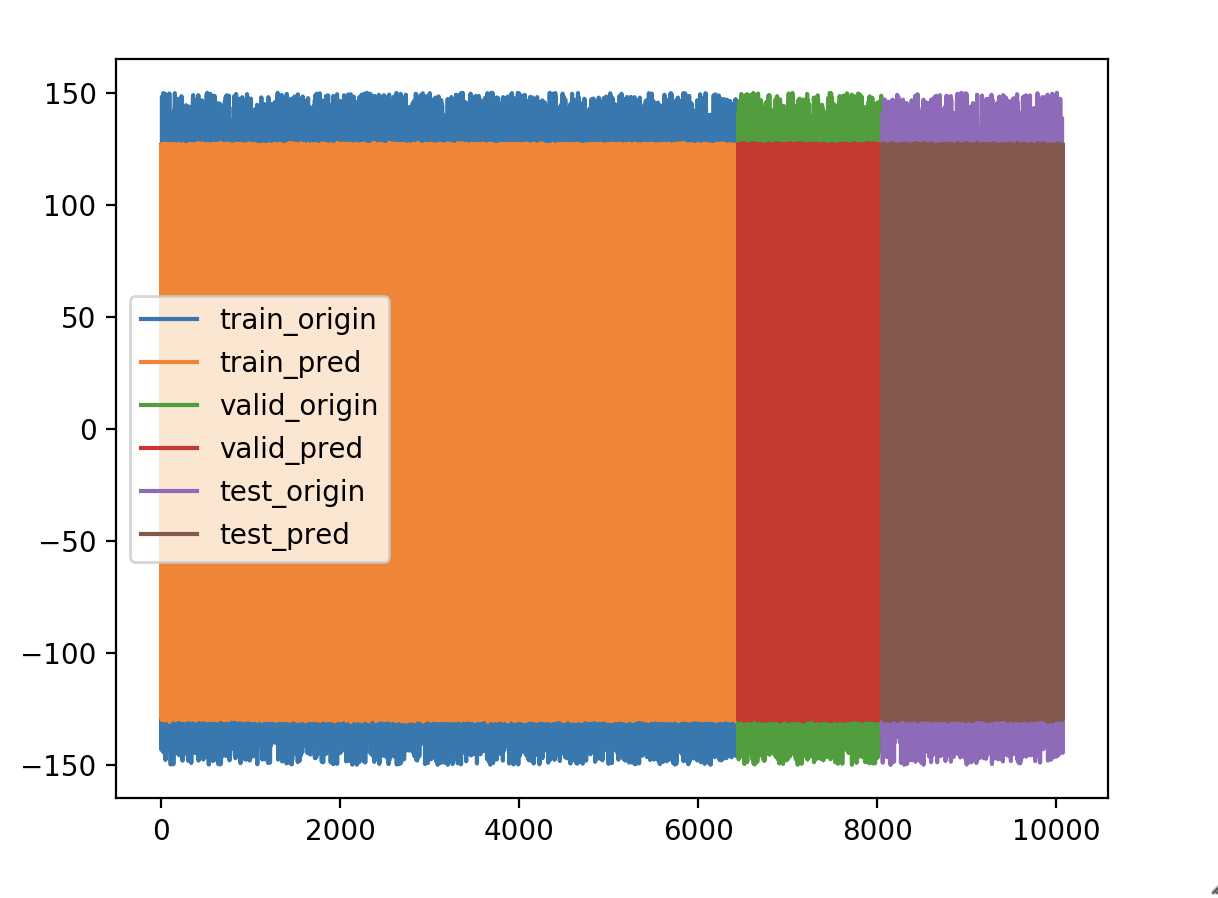
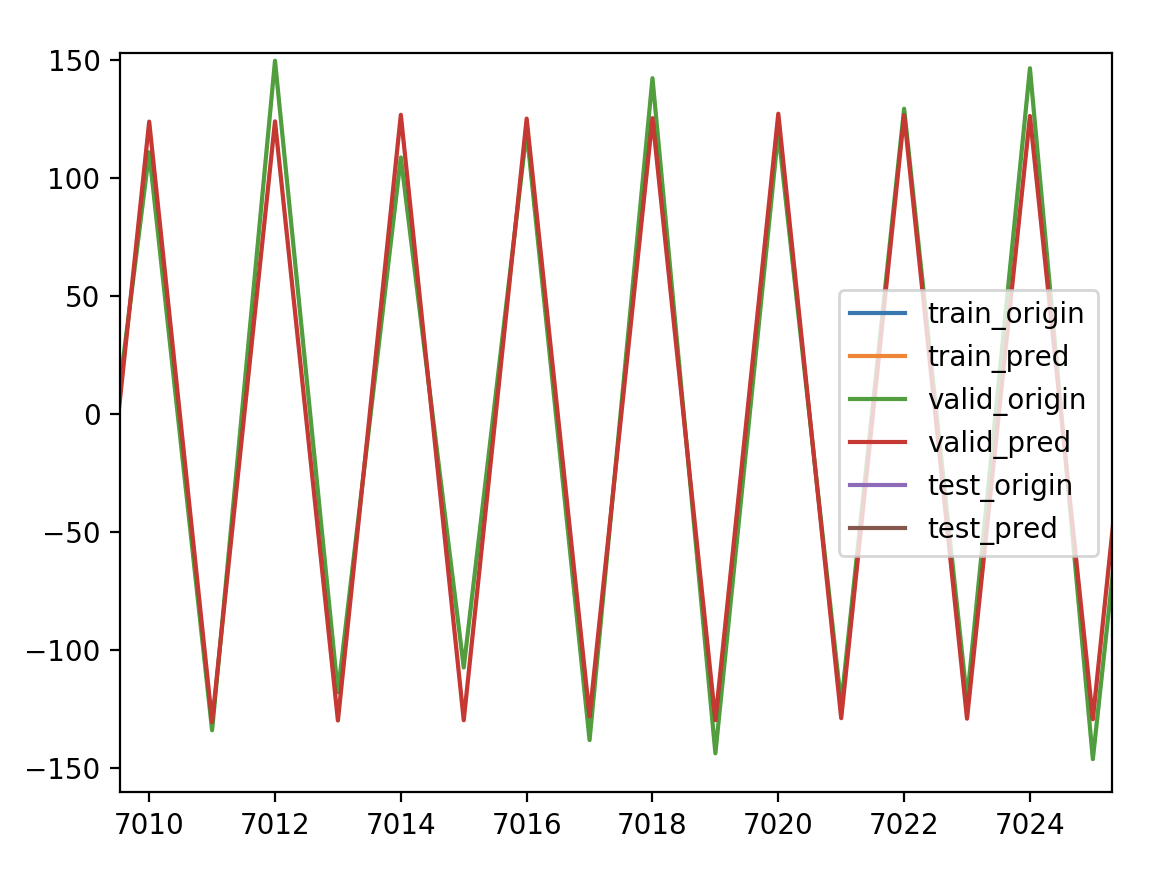
我构造了一正一负的时间序列
正:100~150
负:-150~-100
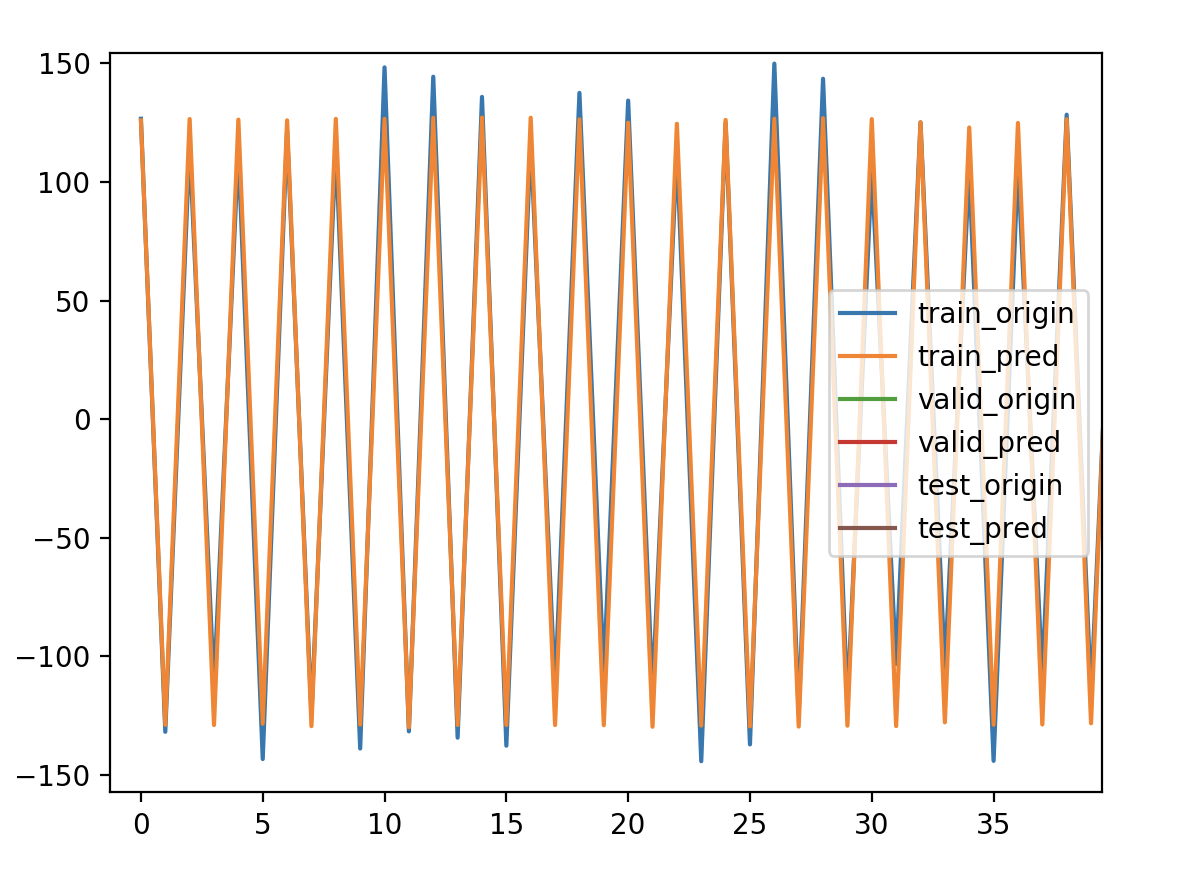
拟合结果
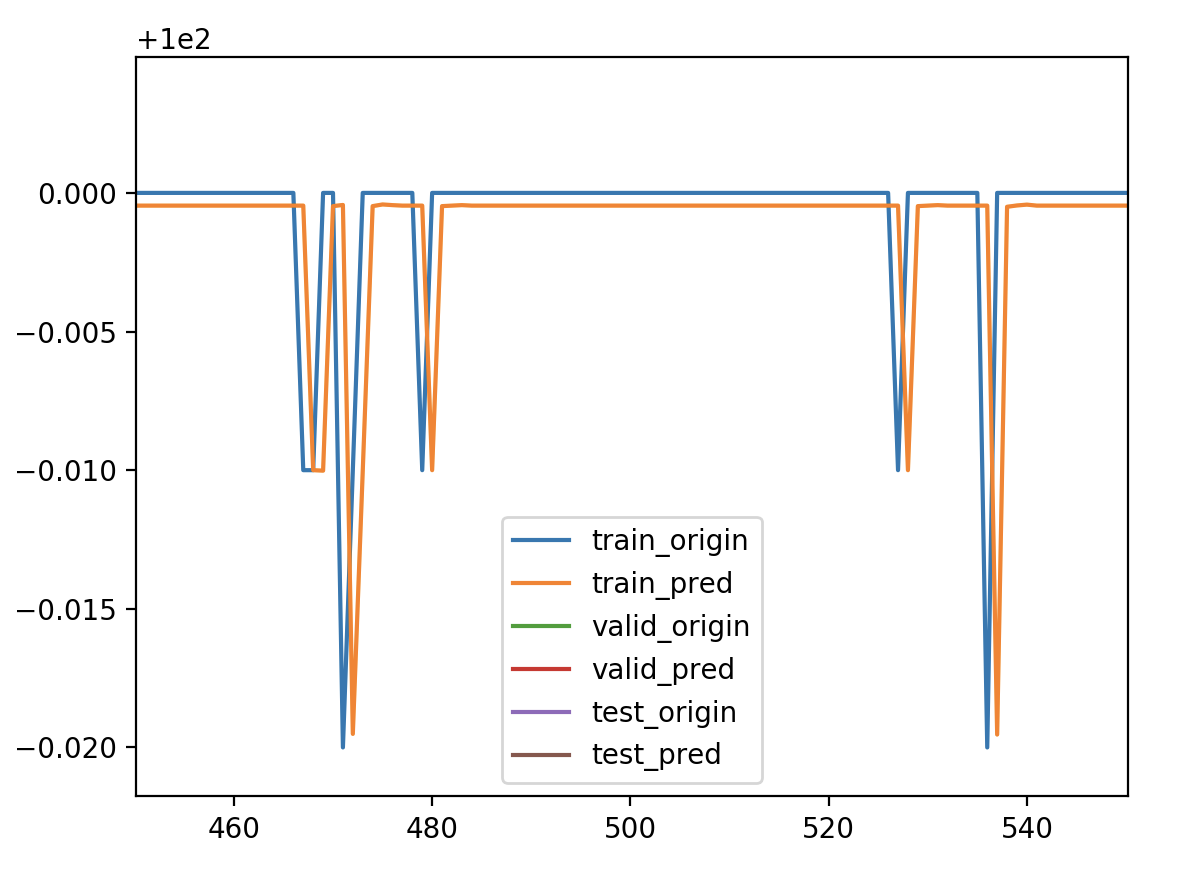
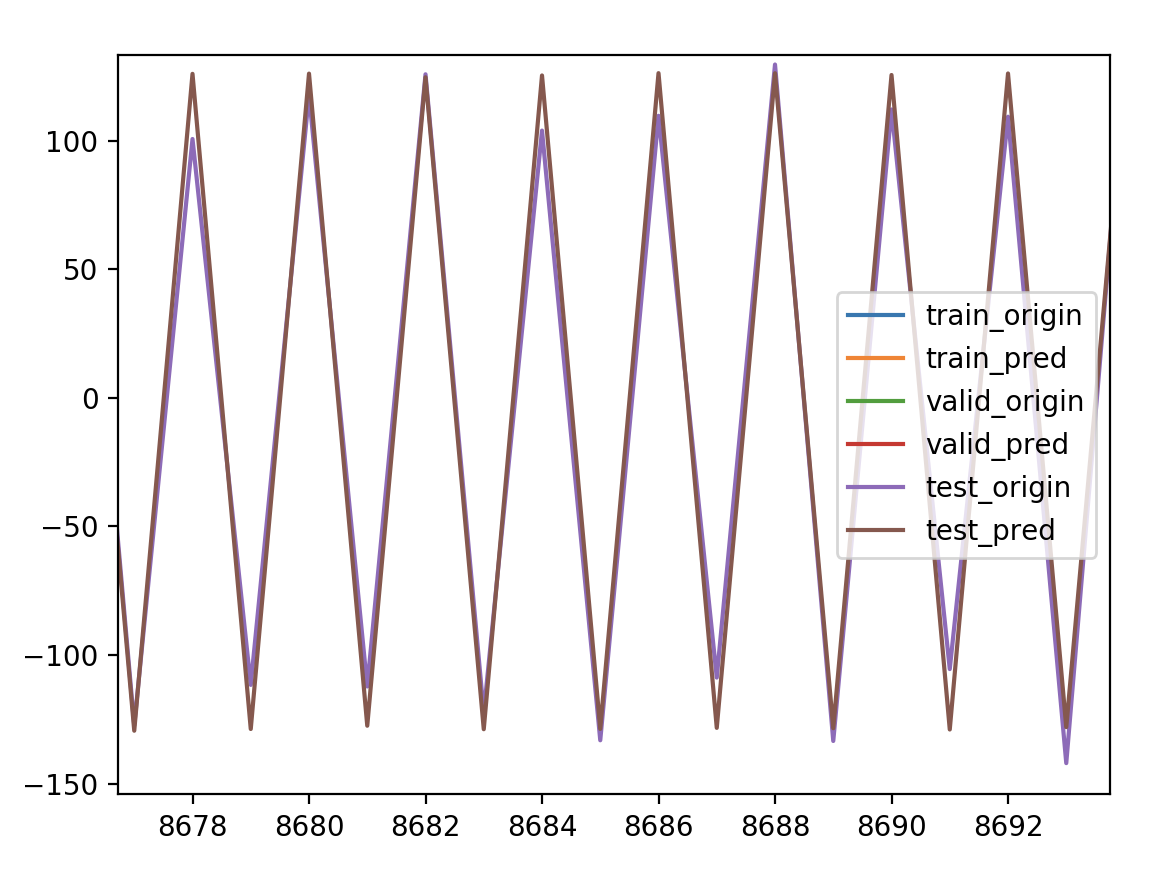
再拉清楚点看看
完全重合,没有错位,没有滞后。是不是说明在平稳的非自相关性的时间序列上就不会有预测值滞后的问题,而并非特征构造的问题,因为LSTM本身就是利用过去的值来预测未来的值,要不然有个timesteps参数作何说明。